자연어 데이터 전처리
1. 데이터 전처리와 텍스트 정제
1.1. 데이터 전처리 소개
자연어처리 모델을 학습하기 위해서, 가장 먼저 데이터를 준비해야 합니다. 자연어 처리(NLP)에서 데이터 전처리는 원시 텍스트 데이터를 기계 학습 모델이 이해하고 처리할 수 있는 형태로 변환하는 단계입니다. 이를 통해, 모델이 학습할 수 있는 형태의 데이터를 준비할 수 있습니다.
데이터 전처리에는 여러가지 기법이 있습니다.
1) 텍스트 정제 (Text Cleaning): 문자, 공백, 특수 기호 등을 제거하여 데이터를 깨끗하게 만드는 과정입니다.
2) 토큰화 (Tokenization): 텍스트를 의미 있는 단위로 분리하는 과정입니다. 이 단위는 보통 단어, 구, 또는 문장일 수 있으며, 이 과정을 통해 생성된 토큰들은 처 리와 분석을 위해 사용됩니다.
3) 정규화(Normalization): 정규화는 텍스트 데이터 내의 변형된 형태를 표준 형태로 통일하는 과정입니다. 예를 들어, "am", "are", "is"의 동사는 "be'로 통일하거 나, 오타나 다른 표기법을 정정하는 것을 포함합니다.
4) 불용어 제거 (Stop Word Removal): 불용어는 자주 등장하지만 분석에는 별 도움이 되지 않는 단어들을 말합니다. 예를 들어, "the", "is", "at" 등과 같은 단어들 이 이에 해당합니다. 이 단어들을 제거하면 데이터 분석의 효율성을 높일 수 있습니다.
5) 임베딩 (Embedding): 임베딩은 단어나 문장 같은 텍스트를 고차원에서 저차원의 연속적인 벡터로 변환하는 기술입니다. 이 벡터는 텍스트의 의미적, 문맥적 특 성을 포착할 수 있으며, 이러한 벡터 표현은 머신러닝 알고리즘에서 사용될 수 있습니다.
이 중에서 이번에는 텍스트 정제(Text Cleaning)에 대해서 공부해 보도록 하겠습니다.
1.2. 텍스트 정제란
텍스트 정제는 자연어 처리(NLP) 프로젝트에서 초기 단계에서 진행합니다. 텍스트 정제 과정에서 학습에 불필요한 텍스트를 제거하거나, 모델이 학습하기 좋은 단어로 텍스트를 대체합니다.
정제되지 않은 데이터는 노이즈가 많고 분석하기 어려울 수 있습니다. 이 과정을 통 유용한 정보를 더 쉽게 추출하고, 머신러닝 모델이 이를 효과적으로 학습할 수 있도록 합니다. 노이즈의 예로는 아래와 같은 것들이 있습니다.
- 오타
- 문법적 오류
- 불필요한 구두점
- 공백 처리
- 특수문자
- 대문자/소문자
- 숫자
- 이모티콘
- 문장부호
- HTML 태그
2. 기본 데이터 정제
2.1. 영문자 소문자 통일
대소문자가 섞여 있을 경우, 같은 단어도 다르게 인식될 수 있습니다. 예를 들어, "Apple", "apple", "APPLE"은 기술적으로 서로 다른 문자열입니다. 이를 모두 소 문자로 변환함으로써 모델이 이 단어들을 동일한 단어로 인식하게 하여 데이터의 일관성을 확보할 수 있습니다.
lower() 문자열에 함수를 이용해 소문자로 변경해줄 수 있습니다.
2.2. 양 끝 공백 정리
텍스트 데이터에는 종종 많은 공백, 탭, 줄바꿈 등이 포함되어 있을 수 있습니다. 이러한 불필요한 공백들은 데이터의 크기를 불필요하게 증가시킬 뿐만 아니라, 데이터 분석을 복잡하게 만들 수 있습니다. 공백을 정리하면 데이터를 더 깔끔하게 유지할 수 있습니다.
2.3. 공백 정리
split() 메소드는 기본적으로 문자열 내의 모든 공백(스페이스, 탭, 줄바꿈)을 기준으로 텍스트를 분리하여 리스트를 반환합니다.
join(...)는 인자로 받은 리스트의 항목들을 문자열로 결합할 때 각 항목 사이에 공백 한 칸을 삽입합니다.
2.4. 특정 문자 대체/제거하기
특정 문자를 제거하거나 대체하는 작업은 텍스트 전처리에서 자주 사용되는 기술입니다. 이를 이용해 커스텀하게 단어를 조작할 수 있기 때문입니다.
str.replace(a, b) 는 a값을 b로 대체하는 메소드입니다.
text = " Hello, World! This is an example text. \t\n"
# 텍스트를 소문자로 변환하세요.
lowercase_text = text.lower()
print(lowercase_text)
# 텍스트의 양 끝 공백을 제거하세요.
cleaned_text = lowercase_text.strip()
print(cleaned_text) hello, world! this is an example text.
hello, world! this is an example text.
# 예시 텍스트
text = "Hello, World! This is an example text with #hash and @mentions."
# 특정 문자 제거: '#'과 '@'
cleaned_text = text.replace('#', '').replace('@', '')
print(cleaned_text)Hello, World! This is an example text with hash and mentions.
3. 정규표현식을 이용한 데이터 정제
정규표현식은 텍스트 데이터에서 특정 패턴을 찾고, 검색하고, 치환하고, 제거하는 데 아주 유용한 도구입니다. 정규표현식을 사용하여 복잡하고 다양한 텍스트 패턴을 효율적으로 처리할 수 있습니다.
3.1. 특수문자 및 불필요한 내용 제거
re.sub() 함수는 정규 표현식을 사용하여 텍스트에서 패턴에 매칭되는 부분을 다른 문자열로 대체할 수 있습니다. 복잡한 패턴이나 여러 문자를 한 번에 제거할 때 유용합니다.
3.2. 다중공백을 하나의 공백으로 축소하기
정규표현식에서 '\s+' 패턴은 공백 문자(whitespace character)를 찾는 데 사용됩니다. 여기서 '\s'는 공백 문자를 나타내며, 이에는 일반적으로 공백(스페이스), 탭(\t), 줄바꿈(n) 등이 포함됩니다. +는 하나 이상의 연속된 문자에 대응됨을 의미합니다.
3.3. 숫자 제거
정규표현식 패턴에서 '\d+'는 여러개의 숫자를 의미합니다. 이를 이용해 숫자를 찾아 제거합니다.
3.4. URL 제거
패턴 설명
- https? : "http"를 찾고, "s"는 선택적입니다. 즉, "http"와 "https" 둘 다 매칭됩니다.
- :// : URL에 필수적인 구분자입니다.
- [#5]+ : 공백이 아닌 문자가 하나 이상 연속되는 부분을 매칭합니다. 즉, 공백을 만나기 전까지의 모든 문자를 포함합니다. 이는 URL의 나머지 부분(도메인 이름 및 이후 경로)을 포괄적으로 매칭하려는 의도입니다.
import re
# 예시 텍스트
text = "Hello, World! This\tis an\nexample text."
# 다중 공백을 하나의 공백으로 축소
pattern = r'\s+'
cleaned_text = re.sub(pattern, ' ', text)
print(cleaned_text)Hello, World! This is an example text.
# 예시 텍스트
text = "This is an example text with numbers 12345 and 67890."
# 모든 숫자 제거
pattern = r'\d+'
cleaned_text = re.sub(pattern, '', text)
print(cleaned_text)This is an example text with numbers and .
4. 이모티콘 다루기
emoji 라이브러리는 파이썬에서 이모티콘을 다루기 위한 편리한 도구를 제공합니다.
4.1. 이모티콘 존재 확인하기
텍스트 내의 모든 이모티콘을 식별하여 리스트로 반환하는 예시입니다. 이를 통해 텍스트 내 이모티콘 사용을 분석할 수 있습니다.

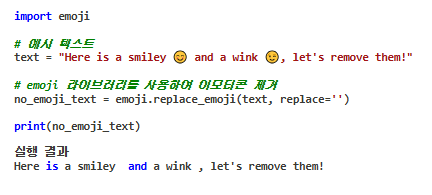
4.2. 이모티콘 제거하기
replace_emoji 메소드는 이모티콘을 특정 문자열로 대체할 수 있습니다. 이를 이용해 이모티콘을 제거합니다.
4.3. 이모티콘을 문자로 대체하기
텍스트에서 이모티콘을 특정 문자로 대체하는 경우, 예를 들어 감정 분석에서 감정을 표현하는 이모티콘을 해당 감정을 나타내는 단어로 변환할 수 있습니다.

5. html에서 문자열 추출
자연어 데이터를 수집하다보면, 웹에서 크롤링 해오는 경우도 있습니다. 이러한 경우 html 태크도 함께 데이터로 들어오게 되는데, 이를 정제해서 문자열을 추출 해야 하는 경우가 종종 있습니다.
HTML에서 문자열을 추출하기 위해 Python에서 가장 널리 사용되는 라이브러리 중 하나는 BeautifulSoup입니다.
아래 예시를 통해 HTML에서 문자열을 추출하는 방법을 확인합니다.

from bs4 import BeautifulSoup
# 예시 HTML 문자열
html_doc = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body>
</html>
"""
# BeautifulSoup 객체 생성, 'html.parser' 사용
soup = BeautifulSoup(html_doc, 'html.parser')
# BeautifulSoup의 get_text() 메소드를 사용하여 HTML에서 모든 텍스트 추출
cleaned_text = soup.get_text()
print(cleaned_text)
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...