Kaggle 경진대회: CIBMTR - Equity in post-HCT Survival Predictions
※ 개요
본 글은 Kaggle 경진대회: CIBMTR - Equity in post-HCT Survival Predictions 의 수상코드를 분석 및 학습하는 것입니다.
'''
캐글 경진대회 : CIBMTR - Equity in post-HCT Survival Predictions
데이터 세트 : 조혈모세포 이식(HSCT)과 관련된 59개 피처로 구성되어 있음
평가방법 : C-index(일치도 지수), efs와 efs_time을 조합하여 순위를 매긴것의 일치도 지수
목적 : efs(생존예측), efs_time(생존시간)을 예측하여 순위를 내는것
'''
※ 머신러닝 예측 파이프 라인
┌────────────────────┐
│ Raw Input Data │
└────────┬───────────┘
▼
┌────────────────────────────────────────────────────────────────────┐
│ Preprocessing │
├────────────────────────────────────────────────────────────────────┤
│ ① Linear Models (MLP 등) │
│ - One-hot encode categorical features │
│ - Normalize continuous features │
│ │
│ ② Tree Models (hist_gbm 등) │
│ - Ordinal encode categorical features │
│ - Normalize continuous features │
│ │
│ ③ Boosting Models │
│ • LightGBM, XGBoost: cast categorical features to 'category' │
│ • CatBoost: cast categorical features to 'str' │
└────────┬───────────────────────────────────────────────────────────┘
▼
┌──────────────────────────────────────────────────────┐
│ EFS Binary Classifier Predictions │
├──────────────────────────────────────────────────────┤
│ - hist_gbm │
│ - lgb_efs_binary_classifier │
│ - xgb_efs_binary_classifier │
│ - cb_efs_binary_classifier │
│ - mlp_sparse_efs_binary_classifier │
│ - mlp_embeddings_efs_prediction │
└────────┬─────────────────────────────────────────────┘
▼
Weighted Sum → efs_ensemble_score
│
▼
┌──────────────────────────────────────────────────────┐
│ Rank Prediction from Survival Models │
├──────────────────────────────────────────────────────┤
│ - hist_gbm_log_efs_time │
│ - hist_gbm_log_km_proba │
│ - hist_gbm_na_cum_hazard │
│ - xgb_log_efs_time │
│ - xgb_log_km_proba │
└────────┬─────────────────────────────────────────────┘
▼
Weighted Sum → rank_ensemble_score
│
▼
┌─────────────────────────────────────────────┐
│ Final Prediction Score │
│ = α * efs_ensemble_score │
│ + β * rank_ensemble_score │
└─────────────────────────────────────────────┘
1. set up
CIBMTR - Equity in post-HCT Survival Predictions
1. Setup
!pip install /kaggle/input/cibmtr-dataset/packages/scikit_learn-1.5.2-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
!pip install /kaggle/input/cibmtr-dataset/packages/xgboost-2.1.3-py3-none-manylinux_2_28_x86_64.whlimport warnings
from pathlib import Path
import pickle
import yaml
from tqdm import tqdm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import OneHotEncoder, OrdinalEncoder, StandardScaler
import lightgbm as lgb
import xgboost as xgb
import catboost as cb
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader, SequentialSamplerwarnings.filterwarnings('ignore')
competition_dataset_directory = Path('/kaggle/input/equity-post-HCT-survival-predictions')
gunes_external_dataset_directory = Path('/kaggle/input/cibmtr-dataset')
pd.set_option('display.max_rows', 1000)
pd.set_option('display.max_columns', 1000)df = pd.read_csv(competition_dataset_directory / 'test.csv')
if df.shape[0] == 3:
df = pd.read_csv(competition_dataset_directory / 'train.csv')
df = pd.concat((
df,
pd.read_csv(gunes_external_dataset_directory / 'folds.csv')
), axis=1, ignore_index=False)
print(f'Dataset Shape: {df.shape}')
display(df)Dataset Shape: (28800, 67)
※ 코드 분석
train 데이터셋에 folds 를 붙임 (folds는 7개임)
2. Preprocessing
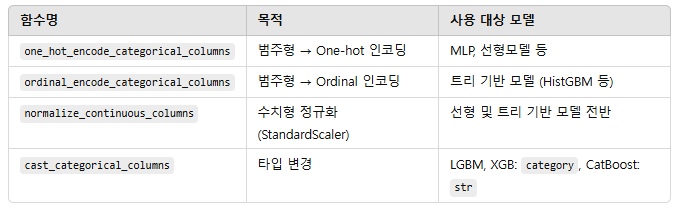
def one_hot_encode_categorical_columns(df, categorical_columns, transformer_directory, load_transformers=False):
"""
One-hot encode given categorical columns and concatenate them to given dataframe
Parameters
----------
df: pandas.DataFrame
Dataframe with categorical columns
categorical_columns: list
List of categorical columns
transformer_directory: str or pathlib.Path
Path of the serialized transformers
load_transformers: bool
Whether to load transformers from the given transformer directory or not
Returns
-------
df: pandas.DataFrame
Dataframe with encoded categorical columns
"""
Path(transformer_directory).mkdir(parents=True, exist_ok=True)
for column in categorical_columns:
if load_transformers:
with open(transformer_directory / f'{column}_one_hot_encoder.pickle', mode='rb') as f:
encoder = pickle.load(f)
encoded = encoder.transform(df[column].values.reshape(-1, 1))
encoded = pd.DataFrame(encoded, columns=encoder.get_feature_names_out([column]), index=df.index)
df = pd.concat((df, encoded), axis=1, ignore_index=False)
else:
encoder = OneHotEncoder(
categories='auto',
drop=None,
sparse_output=False,
dtype=np.uint8,
handle_unknown='ignore',
min_frequency=128
)
encoded = encoder.fit_transform(df[column].values.reshape(-1, 1))
encoded = pd.DataFrame(encoded, columns=encoder.get_feature_names_out([column]), index=df.index)
df = pd.concat((df, encoded), axis=1, ignore_index=False)
with open(transformer_directory / f'{column}_one_hot_encoder.pickle', mode='wb') as f:
pickle.dump(encoder, f)
return df
def ordinal_encode_categorical_columns(df, categorical_columns, transformer_directory, load_transformers=False):
"""
Ordinal encode given categorical columns and concatenate them to given dataframe
Parameters
----------
df: pandas.DataFrame
Dataframe with categorical columns
categorical_columns: list
List of categorical columns
transformer_directory: str or pathlib.Path
Path of the serialized transformers
load_transformers: bool
Whether to load transformers from the given transformer directory or not
Returns
-------
df: pandas.DataFrame
Dataframe with encoded categorical columns
"""
Path(transformer_directory).mkdir(parents=True, exist_ok=True)
for column in categorical_columns:
column_dtype = df[column].dtype
fill_value = 'missing' if column_dtype == object else -1
if load_transformers:
with open(transformer_directory / f'{column}_ordinal_encoder.pickle', mode='rb') as f:
encoder = pickle.load(f)
df[f'{column}_encoded'] = encoder.transform(df[column].fillna(fill_value).values.reshape(-1, 1))
else:
encoder = OrdinalEncoder(
categories='auto',
dtype=np.int32,
handle_unknown='use_encoded_value',
unknown_value=-1,
encoded_missing_value=np.nan,
)
df[f'{column}_encoded'] = encoder.fit_transform(df[column].fillna(fill_value).values.reshape(-1, 1))
with open(transformer_directory / f'{column}_ordinal_encoder.pickle', mode='wb') as f:
pickle.dump(encoder, f)
return df
def normalize_continuous_columns(df, continuous_columns, transformer_directory, load_transformers=False):
"""
Normalize continuous columns and concatenate them to given dataframe
Parameters
----------
df: pandas.DataFrame
Dataframe with continuous columns
continuous_columns: list
List of continuous columns
transformer_directory: str or pathlib.Path
Path of the serialized transformers
load_transformers: bool
Whether to load transformers from the given transformer directory or not
Returns
-------
df: pandas.DataFrame
Dataframe with encoded continuous columns
"""
Path(transformer_directory).mkdir(parents=True, exist_ok=True)
if load_transformers:
with open(transformer_directory / 'standard_scaler.pickle', mode='rb') as f:
normalizer = pickle.load(f)
normalized_column_names = [f'{column}_normalized' for column in continuous_columns]
df[normalized_column_names] = normalizer.transform(df[continuous_columns].fillna(df[continuous_columns].median()).values)
else:
normalizer = StandardScaler()
normalizer.fit(df[continuous_columns].values)
normalized_column_names = [f'{column}_normalized' for column in continuous_columns]
df[normalized_column_names] = normalizer.transform(df[continuous_columns].fillna(df[continuous_columns].median()).values)
with open(transformer_directory / 'standard_scaler.pickle', mode='wb') as f:
pickle.dump(normalizer, f)
return dfdef cast_categorical_columns(df, categorical_columns, dtype):
"""
Cast given categorical columns to category or str
Parameters
----------
df: pandas.DataFrame
Dataframe with categorical columns
categorical_columns: list
Array of categorical column names
dtype: str ('category' or str)
Data type of the categorical column
Returns
-------
df: pandas.DataFrame
Dataframe with casted categorical columns
"""
for column in categorical_columns:
df[f'{column}_{dtype.__name__ if dtype == str else dtype}'] = df[column].astype(dtype)
return dfcategorical_columns = [
'dri_score', 'psych_disturb', 'cyto_score', 'diabetes', 'hla_match_c_high', 'hla_high_res_8', 'tbi_status',
'arrhythmia', 'hla_low_res_6', 'graft_type', 'vent_hist', 'renal_issue', 'pulm_severe', 'prim_disease_hct',
'hla_high_res_6', 'cmv_status', 'hla_high_res_10', 'hla_match_dqb1_high', 'tce_imm_match', 'hla_nmdp_6',
'hla_match_c_low', 'rituximab', 'hla_match_drb1_low', 'hla_match_dqb1_low', 'prod_type', 'cyto_score_detail',
'conditioning_intensity', 'ethnicity', 'year_hct', 'obesity', 'mrd_hct', 'in_vivo_tcd', 'tce_match',
'hla_match_a_high', 'hepatic_severe', 'prior_tumor', 'hla_match_b_low', 'peptic_ulcer', 'hla_match_a_low',
'gvhd_proph', 'rheum_issue', 'sex_match', 'hla_match_b_high', 'race_group', 'comorbidity_score', 'karnofsky_score',
'hepatic_mild', 'tce_div_match', 'donor_related', 'melphalan_dose', 'hla_low_res_8', 'cardiac', 'hla_match_drb1_high',
'pulm_moderate', 'hla_low_res_10'
]
continuous_columns = [
'donor_age', 'age_at_hct'
]
transformer_directory = gunes_external_dataset_directory / 'transformers'df = df.fillna(np.nan)
# One-hot encode categorical columns for linear models
df = one_hot_encode_categorical_columns(
df=df,
categorical_columns=categorical_columns,
transformer_directory=transformer_directory,
load_transformers=True
)
# Ordinal encode categorical columns for tree models
df = ordinal_encode_categorical_columns(
df=df,
categorical_columns=categorical_columns,
transformer_directory=transformer_directory,
load_transformers=True
)
# Normalize continuous columns for linear models
df = normalize_continuous_columns(
df=df,
continuous_columns=continuous_columns,
transformer_directory=transformer_directory,
load_transformers=True
)
# Cast categorical columns to category for LightGBM and XGBoost
df = cast_categorical_columns(
df=df,
categorical_columns=categorical_columns + continuous_columns,
dtype='category'
)
# Cast categorical columns to str for CatBoost
df = cast_categorical_columns(
df=df,
categorical_columns=categorical_columns + continuous_columns,
dtype=str
)
print(f'Transformed Test Set Shape: {df.shape}')
display(df)
28800 rows × 538 columns
※ 코드 구조 분석
이후 사용될 모델에 맞게 각각 전처리를 하고 test (df) 파일에 계속 합치는 구조

3. Sklearn Models
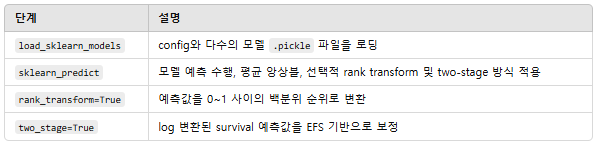
def load_sklearn_models(model_directory):
"""
Load trained sklearn models from given model directory
Parameters
----------
model_directory: str or pathlib.Path
Path-like string of the model directory
Returns
-------
config: dict
Dictionary of model configurations
models: dict {model_file_name: model}
Dictionary of model file names as keys and model objects as values
"""
config_path = model_directory / 'config.yaml'
config = yaml.load(open(config_path), Loader=yaml.FullLoader)
models = {}
for model_path in tqdm(sorted(list(model_directory.glob('model*')))):
model_path = str(model_path)
with open(model_path, mode='rb') as f:
model = pickle.load(f)
model_file_name = model_path.split('/')[-1].split('.')[0]
models[model_file_name] = model
print(f'Loaded {model.__class__.__name__} from {model_path}')
return config, models
def sklearn_predict(df, model_name, config, models, rank_transform=True, two_stage=False, folds=None):
"""
Predict given dataframe with given models and configurations
Parameters
----------
df: pandas.DataFrame
Dataframe with features
model_name: str
Name of the model that will be used on the prediction column
config: dict
Dictionary of model configurations
models: dict {model_file_name: model}
Dictionary of model file names as keys and model objects as values
rank_transform: bool
Whether to do rank transform on single model predictions or not
two_stage: bool
Whether to do two stage or not
Returns
-------
df: pandas.DataFrame
Dataframe with prediction column
"""
prediction_column = f'{model_name}_prediction'
df[prediction_column] = 0.
if two_stage:
reg_1_prediction_column = f'{model_name}_reg_1_prediction'
df[reg_1_prediction_column] = 0.
for model_file_name, model in tqdm(models.items()):
if config['training']['task'] == 'classification':
model_predictions = model.predict_proba(df[config['training']['features']])[:, 1]
else:
model_predictions = model.predict(df[config['training']['features']])
if two_stage:
df[reg_1_prediction_column] += model_predictions / len(models)
if config['training']['target'] in ['log_efs_time']:
model_predictions = df['efs_prediction'] / np.exp(model_predictions)
elif config['training']['target'] in ['log_km_survival_probability', 'na_cumulative_hazard']:
model_predictions = df['efs_prediction'] * np.exp(model_predictions)
if rank_transform:
model_predictions = pd.Series(model_predictions).rank(pct=True).values
print(f'{model.__class__.__name__} Model {model_file_name} Predictions - Mean: {np.mean(model_predictions):.4f} Std: {np.std(model_predictions):.4f} Min: {np.min(model_predictions):.4f} Max: {np.max(model_predictions):.4f}')
df[prediction_column] += model_predictions / len(models)
return df
※ 코드 구조 분석
Sklearn 모델의 하이퍼파라미터 설정이 작성된 config 파일을 로드하여 적용하고 필요한 경우 two-stage 예측이나 rank transform까지 하여 예측함
┌──────────────────────────────┐
│ model_directory (Path) │
└────────────┬─────────────────┘
▼
┌────────────────────────────┐
│ Load config.yaml │◄────────────┐
└────────────────────────────┘ │
▼ │
┌────────────────────────────┐ │
│ Load model*.pickle files │◄──────┐ │
│ → models: dict │ │ │
└────────────────────────────┘ │ │
▼ │ │
Returned by │ │
┌────────────────────┐ ┌──────────────────────┐
│ config (dict) │ │ models (dict) │
└────────────────────┘ └──────────────────────┘
▼ ▼
┌────────────────────────────────────────────────────┐
│ sklearn_predict(df, model_name, ...) │
└────────────────────────────────────────────────────┘
▼
┌────────────────────────────────────────────────────┐
│ Initialize prediction_column = 0 │
│ (ex: hist_gbm_prediction) │
└────────────────────────────────────────────────────┘
▼
Loop over models
▼
┌────────────────────────────────────────────┐
│ model.predict_proba() or model.predict() │ ← depends on task type
└────────────────────────────────────────────┘
▼
┌─────────────────────────────────────────────────────────────────┐
│ If two_stage: │
│ - Save reg_1_prediction │
│ - Adjust prediction based on log_efs_time or other targets │
└─────────────────────────────────────────────────────────────────┘
▼
┌────────────────────────────────────┐
│ If rank_transform: │
│ - Apply rank pct transform │
└────────────────────────────────────┘
▼
┌────────────────────────────────────────────────────────┐
│ Add model_prediction / n_models to prediction_column │
└────────────────────────────────────────────────────────┘
▼
┌───────────────────────────────────────┐
│ Return df with new prediction column │
└───────────────────────────────────────┘
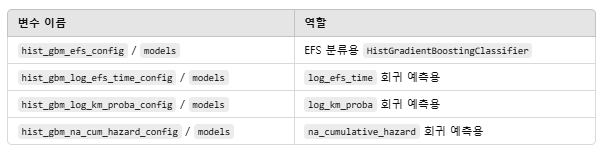
hist_gbm_efs_config, hist_gbm_efs_models = load_sklearn_models(model_directory=gunes_external_dataset_directory / 'hist_gradient_boosting_classifier_efs')
hist_gbm_log_efs_time_config, hist_gbm_log_efs_time_models = load_sklearn_models(model_directory=gunes_external_dataset_directory / 'hist_gradient_boosting_regressor_log_efs_time')
hist_gbm_log_km_proba_config, hist_gbm_log_km_proba_models = load_sklearn_models(model_directory=gunes_external_dataset_directory / 'hist_gradient_boosting_regressor_log_km_proba')
hist_gbm_na_cum_hazard_config, hist_gbm_na_cum_hazard_models = load_sklearn_models(model_directory=gunes_external_dataset_directory / 'hist_gradient_boosting_regressor_na_cum_hazard')
※ 코드 구조 분석
여러 개의 HistGradientBoosting 기반 모델들을 load_sklearn_models() 함수로 불러오는 구조
모델마다 목적이 다르고 (EFS 분류, 생존 시간 회귀 등), 모델 경로에 따라 각각의 config와 model dict가 만들어지는 구조
이후 나올 모델들인 Light GBM Models, XGBoost Models, CatBoost Models 들도 구조가 똑같습니다.
Raw Model Directories
┌────────────────────────┬─────────────────────────────┬────────────────────────────┬──────────────────────────────────────┐
│ hist_gradient_boosting │ hist_gradient_boosting │ hist_gradient_boosting │ hist_gradient_boosting │
│ _classifier_efs │ _regressor_log_efs_time │ _regressor_log_km_proba │ _regressor_na_cum_hazard │
└────────────┬───────────┴────────────┬────────────────┴────────────┬──────────────┴─────────────┬─────────────────────────────┘
▼ ▼ ▼ ▼
┌─────────────────────┐ ┌────────────────────────┐ ┌────────────────────────┐ ┌──────────────────────────────┐
│ load_sklearn_models │ │ load_sklearn_models │ │ load_sklearn_models │ │ load_sklearn_models │
└────────┬────────────┘ └────────┬────────────────┘ └────────┬────────────────┘ └────────┬────────────────────────┘
▼ ▼ ▼ ▼
┌──────────────────────┐ ┌────────────────────────────┐ ┌────────────────────────────┐ ┌──────────────────────────────────┐
│ hist_gbm_efs_config │ │ hist_gbm_log_efs_time_config│ │ hist_gbm_log_km_proba_config│ │ hist_gbm_na_cum_hazard_config │
│ hist_gbm_efs_models │ │ hist_gbm_log_efs_time_models│ │ hist_gbm_log_km_proba_models│ │ hist_gbm_na_cum_hazard_models │
└──────────────────────┘ └────────────────────────────┘ └────────────────────────────┘ └──────────────────────────────────┘
4. Light GBM Models
def load_lgb_model(model_directory):
"""
Load trained LightGBM models from given path
Parameters
----------
model_directory: str or pathlib.Path
Path-like string of the model directory
Returns
-------
config: dict
Dictionary of model configurations
models: dict
Dictionary of model file names as keys and model objects as values
"""
config_path = model_directory / 'config.yaml'
config = yaml.load(open(config_path), Loader=yaml.FullLoader)
models = {}
for model_path in tqdm(sorted(list(model_directory.glob('model*')))):
model_path = str(model_path)
model = lgb.Booster(model_file=model_path)
model_file_name = model_path.split('/')[-1].split('.')[0]
models[model_file_name] = model
print(f'Loaded LightGBM Model from {model_path}')
return config, models
def lgb_predict(df, model_name, config, models, rank_transform, two_stage):
"""
Predict given dataframe with given models and configurations
Parameters
----------
df: pandas.DataFrame
Dataframe with features
model_name: str
Name of the model that will be used on the prediction column
config: dict
Dictionary of model configurations
models: dict {model_file_name: model}
Dictionary of model file names as keys and model objects as values
rank_transform: bool
Whether to do rank transform on single model predictions or not
two_stage: bool
Whether to do two stage or not
Returns
-------
df: pandas.DataFrame
Dataframe with prediction column
"""
prediction_column = f'{model_name}_prediction'
df[prediction_column] = 0.
if two_stage:
reg_1_prediction_column = f'{model_name}_reg_1_prediction'
df[reg_1_prediction_column] = 0.
for model_file_name, model in tqdm(models.items()):
model_predictions = model.predict(
df[config['training']['features']],
num_iteration=config['fit_parameters']['boosting_rounds']
)
if two_stage:
df[reg_1_prediction_column] += model_predictions / len(models)
if config['training']['target'] == 'log_efs_time':
model_predictions = df['efs_prediction'] / np.exp(model_predictions)
elif config['training']['target'] == 'log_km_survival_probability':
model_predictions = df['efs_prediction'] * np.exp(model_predictions)
if rank_transform:
model_predictions = pd.Series(model_predictions).rank(pct=True).values
print(f'LightGBM Model {model_file_name} Predictions - Mean: {np.mean(model_predictions):.4f} Std: {np.std(model_predictions):.4f} Min: {np.min(model_predictions):.4f} Max: {np.max(model_predictions):.4f}')
df[prediction_column] += model_predictions / len(models)
return dflgb_efs_binary_classifier_config, lgb_efs_binary_classifier_models = load_lgb_model(gunes_external_dataset_directory / 'lightgbm_efs_binary_classifier')
5. XGBoost Models
def load_xgb_model(model_directory):
"""
Load trained XGBoost models from given path
Parameters
----------
model_directory: str or pathlib.Path
Path-like string of the model directory
Returns
-------
config: dict
Dictionary of model configurations
models: dict
Dictionary of model file names as keys and model objects as values
"""
config_path = model_directory / 'config.yaml'
config = yaml.load(open(config_path), Loader=yaml.FullLoader)
models = {}
for model_path in tqdm(sorted(list(model_directory.glob('model*')))):
model_path = str(model_path)
model = xgb.Booster()
model.load_model(model_path)
model_file_name = model_path.split('/')[-1].split('.')[0]
models[model_file_name] = model
print(f'Loaded XGBoost Model from {model_path}')
return config, models
def xgb_predict(df, model_name, config, models, rank_transform, two_stage):
"""
Predict given dataframe with given models and configurations
Parameters
----------
df: pandas.DataFrame
Dataframe with features
model_name: str
Name of the model that will be used on the prediction column
config: dict
Dictionary of model configurations
models: dict {model_file_name: model}
Dictionary of model file names as keys and model objects as values
rank_transform: bool
Whether to do rank transform on single model predictions or not
two_stage: bool
Whether to do two stage or not
Returns
-------
df: pandas.DataFrame
Dataframe with prediction column
"""
dataset = xgb.DMatrix(df[config['training']['features']], enable_categorical=True)
prediction_column = f'{model_name}_prediction'
df[prediction_column] = 0.
if two_stage:
reg_1_prediction_column = f'{model_name}_reg_1_prediction'
df[reg_1_prediction_column] = 0.
for model_file_name, model in tqdm(models.items()):
model_predictions = model.predict(dataset)
if two_stage:
df[reg_1_prediction_column] += model_predictions / len(models)
if config['training']['target'] == 'log_efs_time':
model_predictions = df['efs_prediction'] / np.exp(model_predictions)
elif config['training']['target'] == 'log_km_survival_probability':
model_predictions = df['efs_prediction'] * np.exp(model_predictions)
if rank_transform:
model_predictions = pd.Series(model_predictions).rank(pct=True).values
print(f'XGBoost Model {model_file_name} Predictions - Mean: {np.mean(model_predictions):.4f} Std: {np.std(model_predictions):.4f} Min: {np.min(model_predictions):.4f} Max: {np.max(model_predictions):.4f}')
df[prediction_column] += model_predictions / len(models)
return dfxgb_efs_binary_classifier_config, xgb_efs_binary_classifier_models = load_xgb_model(gunes_external_dataset_directory / 'xgboost_efs_binary_classifier')
xgb_log_efs_time_regressor_config, xgb_log_efs_time_regressor_models = load_xgb_model(gunes_external_dataset_directory / 'xgboost_log_efs_time_regressor')
xgb_log_km_proba_regressor_config, xgb_log_km_proba_regressor_models = load_xgb_model(gunes_external_dataset_directory / 'xgboost_log_km_proba_regressor')
6. CatBoost Models
def load_cb_model(model_directory, task):
"""
Load trained CatBoost models from given path
Parameters
----------
model_directory: str or pathlib.Path
Path-like string of the model directory
task: str
Task type of the model
Returns
-------
config: dict
Dictionary of model configurations
models: dict
Dictionary of model file names as keys and model objects as values
"""
config_path = model_directory / 'config.yaml'
config = yaml.load(open(config_path), Loader=yaml.FullLoader)
models = {}
for model_path in tqdm(sorted(list(model_directory.glob('model*')))):
model_path = str(model_path)
if task == 'regression':
model = cb.CatBoostRegressor()
elif task == 'classification':
model = cb.CatBoostClassifier()
model.load_model(model_path)
model_file_name = model_path.split('/')[-1].split('.')[0]
models[model_file_name] = model
print(f'Loaded CatBoost Model from {model_path}')
return config, models
def cb_predict(df, model_name, config, models, rank_transform, two_stage):
"""
Predict given dataframe with given models and configurations
Parameters
----------
df: pandas.DataFrame
Dataframe with features
model_name: str
Name of the model that will be used on the prediction column
config: dict
Dictionary of model configurations
models: dict {model_file_name: model}
Dictionary of model file names as keys and model objects as values
rank_transform: bool
Whether to do rank transform on single model predictions or not
two_stage: bool
Whether to do two stage or not
Returns
-------
df: pandas.DataFrame
Dataframe with prediction column
"""
prediction_column = f'{model_name}_prediction'
df[prediction_column] = 0.
if two_stage:
reg_1_prediction_column = f'{model_name}_reg_1_prediction'
df[reg_1_prediction_column] = 0.
for model_file_name, model in tqdm(models.items()):
if isinstance(model, cb.CatBoostClassifier):
model_predictions = model.predict_proba(df[config['training']['features']])[:, 1]
else:
model_predictions = model.predict(df[config['training']['features']])
if two_stage:
df[reg_1_prediction_column] += model_predictions / len(models)
if config['training']['target'] == 'log_efs_time':
model_predictions = df['efs_prediction'] / np.exp(model_predictions)
elif config['training']['target'] == 'log_km_survival_probability':
model_predictions = df['efs_prediction'] * np.exp(model_predictions)
if rank_transform:
model_predictions = pd.Series(model_predictions).rank(pct=True).values
print(f'CatBoost Model {model_file_name} Predictions - Mean: {np.mean(model_predictions):.4f} Std: {np.std(model_predictions):.4f} Min: {np.min(model_predictions):.4f} Max: {np.max(model_predictions):.4f}')
df[prediction_column] += model_predictions / len(models)
return dfcb_efs_binary_classifier_config, cb_efs_binary_classifier_models = load_cb_model(gunes_external_dataset_directory / 'catboost_efs_binary_classifier', task='classification')
7. NN Models
7-1)
def init_weights(layer):
if isinstance(layer, nn.Linear):
nn.init.xavier_normal_(layer.weight, gain=1.0)
if layer.bias is not None:
nn.init.zeros_(layer.bias)
if isinstance(layer, nn.Embedding):
nn.init.xavier_normal_(layer.weight, gain=1.0)
class FullyConnectedBlock(nn.Module):
def __init__(self, input_dim, hidden_dim):
super(FullyConnectedBlock, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim, bias=True)
self.fc2 = nn.Linear(hidden_dim, input_dim, bias=True)
self.activation = nn.ReLU()
self.dropout = nn.Dropout(0.5)
for fc in [self.fc1, self.fc2]:
init_weights(fc)
def forward(self, x):
x = self.fc1(x)
x = self.activation(x)
x = self.dropout(x)
x = self.fc2(x)
return x
class SparseMLP(nn.Module):
def __init__(self, input_dim, stem_dim, mlp_hidden_dim, n_blocks, output_dim):
super(SparseMLP, self).__init__()
self.stem = nn.Linear(input_dim, stem_dim, bias=True)
self.mlp = nn.Sequential(
*[
FullyConnectedBlock(
input_dim=stem_dim,
hidden_dim=mlp_hidden_dim,
) for _ in range(n_blocks)
]
)
self.head = nn.Linear(stem_dim, output_dim)
def forward(self, x):
x = self.stem(x)
x = self.mlp(x)
outputs = self.head(x)
return outputs
class EmbeddingMLP(nn.Module):
def __init__(self, input_n_categories, input_cont_dim, embedding_dim, stem_dim, mlp_hidden_dim, n_blocks, output_dim):
super(EmbeddingMLP, self).__init__()
self.categorical_embeddings = nn.ModuleList([
nn.Embedding(n_category, embedding_dim) for n_category in input_n_categories
])
for embedding in self.categorical_embeddings:
init_weights(embedding)
embedding_output_dim = len(input_n_categories) * embedding_dim
self.cont_fc = nn.Linear(input_cont_dim, input_cont_dim * 2, bias=True)
init_weights(self.cont_fc)
total_input_dim = embedding_output_dim + (input_cont_dim * 2)
self.stem = nn.Linear(total_input_dim, stem_dim, bias=True)
self.mlp = nn.Sequential(*[
FullyConnectedBlock(input_dim=stem_dim, hidden_dim=mlp_hidden_dim)
for _ in range(n_blocks)
])
self.head = nn.Linear(stem_dim, output_dim)
def forward(self, x):
x_cat = x[:, :-2].long()
x_cont = x[:, -2:]
embedded = [emb(x_cat[:, i]) for i, emb in enumerate(self.categorical_embeddings)]
embedded = torch.cat(embedded, dim=1)
cont_out = self.cont_fc(x_cont)
x = torch.cat([embedded, cont_out], dim=1)
x = self.stem(x)
x = self.mlp(x)
outputs = self.head(x)
return outputs
※ 코드 구조 분석
위의 코드는 두가지 신경망 구성입니다.
1) SparseMLP : 연속형 입력만을 처리하는 MLP
2) EmbeddingMLP : 범주형 + 연속형 입력을 함께 처리하는 MLP (with embedding)

◆ FullyConnectedBlock: 기본 빌딩 블록
[Input]
↓
Linear (in → hidden)
↓
ReLU
↓
Dropout(0.5)
↓
Linear (hidden → in)
↓
[Output]
◆ SparseMLP: 연속형 입력만 받는 MLP
[Continuous Features] (input_dim)
↓
Linear
(input_dim → stem_dim)
↓
┌──────────────────────────┐
│ FullyConnectedBlock x N │ ← Repeated n_blocks times
└──────────────────────────┘
↓
Linear
(stem_dim → output_dim)
↓
[Output]
◆ EmbeddingMLP: 범주형 + 연속형 입력을 함께 받는 구조
[Categorical Indices] [Continuous Features]
│ │
▼ ▼
┌─────────────┐ ┌─────────────────────┐
│ Embedding x N│ │ Linear (cont → 2x) │
└─────────────┘ └─────────────────────┘
│ │
└───────┬────────────┬────────┘
▼
Concatenate All (embedding + cont_fc)
▼
Linear (→ stem_dim)
▼
┌──────────────────────────┐
│ FullyConnectedBlock x N │
└──────────────────────────┘
▼
Linear (stem_dim → output_dim)
▼
[Output]
◆ 공통 초기화
모든 Linear, Embedding 레이어는 Xavier Normal로 weight 초기화
Linear의 bias는 0으로 초기화
7-2)
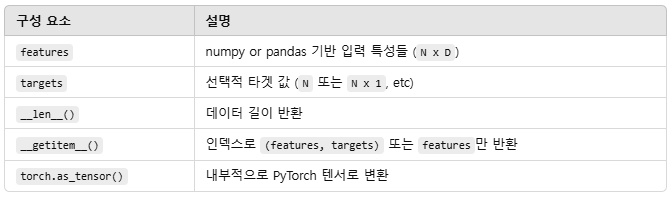
class TabularInMemoryDataset(Dataset):
def __init__(self, features, targets=None):
self.features = features
self.targets = targets
def __len__(self):
"""
Get the length the dataset
Returns
-------
length: int
Length of the dataset
"""
return len(self.features)
def __getitem__(self, idx):
"""
Get the idxth element in the dataset
Parameters
----------
idx: int
Index of the sample (0 <= idx < length of the dataset)
Returns
-------
features: torch.Tensor of shape (n_features)
Features tensor
targets: torch.Tensor of shape (n_targets)
Targets tensor
"""
features = self.features[idx]
features = torch.as_tensor(features, dtype=torch.float)
if self.targets is not None:
targets = self.targets[idx]
targets = torch.as_tensor(targets, dtype=torch.float)
return features, targets
else:
return features
※ 코드 구조 분석
이 클래스는 PyTorch Dataset을 상속해서, tabular 형태의 데이터셋을 메모리에 올려두고 사용하는 구조입니다.
┌────────────────────────────┐
│ TabularInMemoryDataset │
└────────────┬───────────────┘
│
┌───────────────────────┴────────────────────────┐
│ │
▼ ▼
┌────────────────────┐ ┌────────────────────────┐
│ __init__ │ │ __len__ │
└────────────────────┘ └────────────────────────┘
│ - self.features = features │ return len(self.features)
│ - self.targets = targets └────────────────────────┘
└────────────────────┘
│
▼
┌──────────────────────────────┐
│ __getitem__ │
└──────────────────────────────┘
│ Input: idx (int) │
│ ──────────────────────────── │
│ features = features[idx] │
│ → torch.tensor(float32) │
│ │
│ if targets exist: │
│ targets = targets[idx] │
│ → torch.tensor(float32) │
│ return (features, targets)│
│ else: │
│ return features │
└──────────────────────────────┘
7-3)
def load_torch_model(model_directory):
"""
Load trained torch models from given path
Parameters
----------
model_directory: str or pathlib.Path
Path-like string of the model directory
Returns
-------
config: dict
Dictionary of model configurations
models: dict
Dictionary of model file names as keys and model objects as values
"""
config_path = model_directory / 'config.yaml'
config = yaml.load(open(config_path), Loader=yaml.FullLoader)
models = {}
for model_path in tqdm(sorted(list(model_directory.glob('model*')))):
model = eval(config['model']['model_class'])(**config['model']['model_args'])
model_path = str(model_path)
model.load_state_dict(torch.load(model_path, map_location=torch.device('cpu')))
model.eval()
model_file_name = model_path.split('/')[-1].split('.')[0]
models[model_file_name] = model
print(f'Loaded {model.__class__.__name__} Model from {model_path}')
return config, models
def nn_predict(df, model_name, config, models, rank_transform, two_stage):
"""
Predict given dataframe with given models and configurations
Parameters
----------
df: pandas.DataFrame
Dataframe with features
model_name: str
Name of the model that will be used on the prediction column
config: dict
Dictionary of model configurations
models: dict {model_file_name: model}
Dictionary of model file names as keys and model objects as values
rank_transform: bool
Whether to do rank transform on single model predictions or not
two_stage: bool
Whether to do two stage or not
Returns
-------
df: pandas.DataFrame
Dataframe with prediction column
"""
dataset = TabularInMemoryDataset(features=df[config['training']['features']].values)
data_loader = DataLoader(
dataset,
batch_size=2048,
sampler=SequentialSampler(dataset),
pin_memory=False,
drop_last=False,
num_workers=4
)
prediction_column = f'{model_name}_prediction'
df[prediction_column] = 0.
for model_file_name, model in tqdm(models.items()):
model_predictions = []
for inputs in data_loader:
with torch.no_grad():
outputs = model(inputs)
model_predictions.append(outputs)
model_predictions = torch.cat(model_predictions, dim=0).view(-1)
if config['training']['task'] == 'classification':
model_predictions = torch.sigmoid(model_predictions)
model_predictions = model_predictions.numpy()
if two_stage:
if config['training']['target'] == 'log_efs_time':
model_predictions = df['efs_prediction'] / np.exp(model_predictions)
elif config['training']['target'] == 'log_km_survival_probability':
model_predictions = df['efs_prediction'] * np.exp(model_predictions)
if rank_transform:
model_predictions = pd.Series(model_predictions).rank(pct=True).values
print(f'{model.__class__.__name__} Model {model_file_name} Predictions - Mean: {np.mean(model_predictions):.4f} Std: {np.std(model_predictions):.4f} Min: {np.min(model_predictions):.4f} Max: {np.max(model_predictions):.4f}')
df[prediction_column] += model_predictions / len(models)
return df
※ 코드 구조 분석
이 코드는 PyTorch 기반으로 학습된 모델을 로딩하고 추론하는 구조

┌─────────────────────────────┐
│ model_directory (Path) │
└────────────┬────────────────┘
▼
┌─────────────────────────────┐
│ Load config.yaml │
└────────────┬────────────────┘
▼
┌────────────────────────────────────────┐
│ For each 'model*' file in directory: │
│ - eval(model_class)(**model_args) │
│ - load_state_dict from file │
│ - model.eval() │
└────────────┬───────────────────────────┘
▼
┌──────────────────────────────┐
│ return config, models (dict) │
└──────────────────────────────┘
7-4)
mlp_sparse_efs_binary_classifier_config, mlp_sparse_efs_binary_classifier_models = load_torch_model(gunes_external_dataset_directory / 'mlp_sparse_efs_binary_classifier')
mlp_embeddings_efs_binary_classifier_config, mlp_embeddings_efs_binary_classifier_models = load_torch_model(gunes_external_dataset_directory / 'mlp_embeddings_efs_binary_classifier')
※ 코드 구조 분석
load_torch_model() 함수를 사용해서 config와 model들을 가져오는 동일한 구조

Raw Model Directories
┌────────────────────────────────────┬────────────────────────────────────┐
│ mlp_sparse_efs_binary_classifier │ mlp_embeddings_efs_binary_classifier │
└────────────┬───────────────────────┴──────────────────────┬────────────┘
▼ ▼
┌───────────────────────┐ ┌────────────────────────┐
│ load_torch_model() │ │ load_torch_model() │
└────────────┬──────────┘ └────────────┬───────────┘
▼ ▼
┌────────────────────────────────────┐ ┌────────────────────────────────────────┐
│ mlp_sparse_efs_binary_classifier_ │ │ mlp_embeddings_efs_binary_classifier_ │
│ config, models (dict) │ │ config, models (dict) │
└────────────────────────────────────┘ └────────────────────────────────────────┘
8. Binary EFS Predictions
df = sklearn_predict(
df=df,
model_name='hist_gbm_efs',
config=hist_gbm_efs_config,
models=hist_gbm_efs_models,
rank_transform=False,
two_stage=False
)
df = lgb_predict(
df=df,
model_name='lgb_efs',
config=lgb_efs_binary_classifier_config,
models=lgb_efs_binary_classifier_models,
rank_transform=False,
two_stage=False
)
df = xgb_predict(
df=df,
model_name='xgb_efs',
config=xgb_efs_binary_classifier_config,
models=xgb_efs_binary_classifier_models,
rank_transform=False,
two_stage=False
)
df = cb_predict(
df=df,
model_name='cb_efs',
config=cb_efs_binary_classifier_config,
models=cb_efs_binary_classifier_models,
rank_transform=False,
two_stage=False
)
df = nn_predict(
df=df,
model_name='mlp_sparse_efs',
config=mlp_sparse_efs_binary_classifier_config,
models=mlp_sparse_efs_binary_classifier_models,
rank_transform=False,
two_stage=False
)
df = nn_predict(
df=df,
model_name='mlp_embeddings_efs',
config=mlp_embeddings_efs_binary_classifier_config,
models=mlp_embeddings_efs_binary_classifier_models,
rank_transform=False,
two_stage=False
)
df['efs_prediction'] = df['hist_gbm_efs_prediction'] * 0.45 + \
df['lgb_efs_prediction'] * 0.05 + \
df['xgb_efs_prediction'] * 0.05 + \
df['cb_efs_prediction'] * 0.2 + \
df['mlp_sparse_efs_prediction'] * 0.125 + \
df['mlp_embeddings_efs_prediction'] * 0.125
※ 코드 구조 분석
다양한 모델을 사용해 EFS 이진 분류 예측을 수행
총 6개의 모델이 있고, 각각 예측 결과를 DataFrame df에 새로운 열로 저장
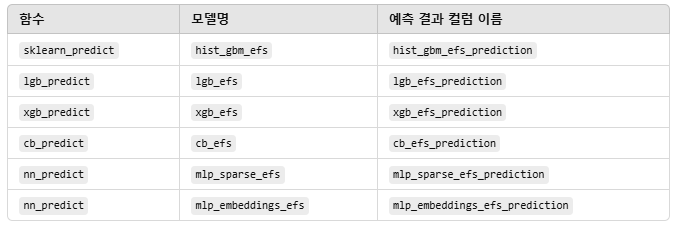
그 후, 각 모델의 EFS 예측값을 가중합(Weighted Sum) 하여 efs_prediction 컬럼을 생성(가중치는 상관관계 기반)
결과적으로, 개별 모델의 예측을 통합한 앙상블 예측값 생성
9. Rank Predictions
df = sklearn_predict(
df=df,
model_name='hist_gbm_log_efs_time',
config=hist_gbm_log_efs_time_config,
models=hist_gbm_log_efs_time_models,
rank_transform=True,
two_stage=True
)
df = sklearn_predict(
df=df,
model_name='hist_gbm_log_km_proba',
config=hist_gbm_log_km_proba_config,
models=hist_gbm_log_km_proba_models,
rank_transform=True,
two_stage=True
)
df = sklearn_predict(
df=df,
model_name='hist_gbm_na_cum_hazard',
config=hist_gbm_na_cum_hazard_config,
models=hist_gbm_na_cum_hazard_models,
rank_transform=True,
two_stage=True
)
df = xgb_predict(
df=df,
model_name='xgb_log_efs_time',
config=xgb_log_efs_time_regressor_config,
models=xgb_log_efs_time_regressor_models,
rank_transform=True,
two_stage=True
)
df = xgb_predict(
df=df,
model_name='xgb_log_km_proba',
config=xgb_log_km_proba_regressor_config,
models=xgb_log_km_proba_regressor_models,
rank_transform=True,
two_stage=True
)df['prediction'] = df['hist_gbm_log_efs_time_prediction'] * 0.3 + \
df['hist_gbm_log_km_proba_prediction'] * 0.3 + \
df['hist_gbm_na_cum_hazard_prediction'] * 0.3 + \
df['xgb_log_efs_time_prediction'] * 0.05 + \
df['xgb_log_km_proba_prediction'] * 0.05
※ 코드 구조 분석
모든 모델에 대해 rank_transform=True와 two_stage=True가 설정되어 있어서,
EFS 예측값(efs_prediction)을 기반으로 보정된 생존 순위 예측값 생성
- two_stage = True:
→ 생존 예측값을 efs_prediction과 결합하여 보정 (exp/log 기반 수식 사용) - rank_transform = True:
→ 예측값을 0~1 사이 백분위(rank percentile)로 정규화
→ C-index와 같은 순위 기반 평가 지표에 적합하게 만듦

11. Submission
df_submission = pd.read_csv(competition_dataset_directory / 'sample_submission.csv')
df_submission['prediction'] = df['prediction']
df_submission.to_csv('submission.csv', index=False)
df_submission.to_csv('gunes_submission.csv', index=False)
display(df_submission)