회귀 : 커머스 제품 판매량 예측 1
※ 탐색적 데이터 분석을 통해 데이터 이해하기
탐색적 데이터 분석(EDA, Exploratory Data Analysis)을 통해 데이터를 깊이 있게 이해하는 방법에 대해 학습합니다.
현대 디지털 시대에서 온라인 판매는 상품과 서비스를 전달하는 핵심 채널로 자리매김했습니다. 이와 함께 온라인 판매 채널에서 수집되는 대규모 데이터는 단순한 정보의 형태를 넘어, 판매 환경에서 귀중한 통찰력을 얻는 중요한 자산이 되었습니다.
EDA는 데이터 사이언스 프로젝트의 핵심 부분으로, 데이터의 기본적인 정보를 파악하고, 각 피처의 분포를 확인하며, 피처들 간의 연관성을 탐색하는 과정입니다. 이를 통해 각 온라인 채널의 판매량을 예측하는 데 필요한 기초를 다질 수 있습니다.
이번에는 온라인 판매 데이터를 분석하여, 효율적인 재고 관리와 타겟 마케팅 전략을 세우기 위한 통찰력을 얻고, 이를 바탕으로 판매 예측 AI 모델을 개발하는 데 인사이트를 얻는 것이 목표입니다.
1. 데이터셋 이해
data = pd.read_csv('train.csv')
data.head(5) #2022년 1월1일 ~ 2023년 4월 24일까지의 수요
2. 대분류 카테고리별 그래프 EDA
grouped_data = data.groupby('대분류', group_keys=False)\
.apply(lambda x:
x.sample(
n=min(5, len(x)),
random_state=1
)
)
# '대분류' 카테고리별로 그래프 생성
for category in grouped_data['대분류'].unique():
category_data = grouped_data[grouped_data['대분류'] == category]
# 날짜 열 선택
sales_data = category_data.iloc[:, 7:]
fig, ax = plt.subplots(figsize=(15, 5))
sales_data.set_index(category_data['제품']).transpose().plot(ax=ax)
# 그래프 제목 및 라벨 설정
ax.set_title(f'{category}')
ax.set_xlabel('Date')
ax.set_ylabel('Demand')
ax.legend()
# 그래프 표시
plt.show()
※ 결과해석
생성된 그래프를 통해 각 대분류 카테고리별 제품의 판매 추세와 패턴을 관찰하였으나, 특정 시즌이나 기간에 따른 판매량의 증가나 감소 추이와 제품 간 판매량의 유사성 비교에서 도움이 되는 정보를 얻지 못했습니다.
3. 중분류 카테고리별 그래프 EDA
grouped_data = data.groupby('중분류', group_keys=False).apply(lambda x: x.sample(n=min(10, len(x)), random_state=1))
i=0
for category in grouped_data['중분류'].unique():
if(i == 5):
break
i+=1
category_data = grouped_data[grouped_data['중분류'] == category]
sales_data = category_data.iloc[:, 7:]
fig, ax = plt.subplots(figsize=(15, 5))
sales_data.set_index(category_data['제품']).transpose().plot(ax=ax)
ax.set_title(f'{category}')
ax.set_xlabel('Date')
ax.set_ylabel('Demand')
ax.legend()
plt.show()



※ 결과해석
생성된 그래프를 통해 각 중분류 카테고리별 제품의 판매 추세와 패턴을 관찰하였으나, 특정 시즌이나 기간에 따른 판매량의 증가나 감소 추이와 제품 간 판매량의 유사성 비교에서 도움이 되는 정보를 얻지 못했습니다.
4. 소분류 카테고리별 그래프 EDA
grouped_data = data.groupby('소분류', group_keys=False).apply(lambda x: x.sample(n=min(10, len(x)), random_state=1))
i = 0
for category in grouped_data['소분류'].unique():
if(i == 5):
break
i+=1
category_data = grouped_data[grouped_data['소분류'] == category]
sales_data = category_data.iloc[:, 7:]
fig, ax = plt.subplots(figsize=(15, 5))
sales_data.set_index(category_data['제품']).transpose().plot(ax=ax)
ax.set_title(f'{category}')
ax.set_xlabel('Date')
ax.set_ylabel('Demand')
ax.legend()
plt.show()


※ 결과해석
생성된 그래프를 통해 각 소분류 카테고리별 제품의 판매 추세와 패턴을 관찰하였으나, 특정 시즌이나 기간에 따른 판매량의 증가나 감소 추이와 제품 간 판매량의 유사성 비교에서 도움이 되는 정보를 얻지 못했습니다.
5. 브랜드 카테고리별 그래프 EDA
data = pd.read_csv('train.csv')
grouped_data = data.groupby('브랜드', group_keys=False).apply(lambda x: x.sample(n=min(10, len(x)), random_state=1))
i = 0
for category in grouped_data['브랜드'].unique():
if(i == 5):
break
i+=1
category_data = grouped_data[grouped_data['브랜드'] == category]
sales_data = category_data.iloc[:, 7:]
fig, ax = plt.subplots(figsize=(15, 5))
sales_data.set_index(category_data['제품']).transpose().plot(ax=ax)
ax.set_title(f'{category}')
ax.set_xlabel('Date')
ax.set_ylabel('Demand')
ax.legend()
plt.show()


※ 결과해석
대분류, 중분류, 소분류와 같이 불분명한 카테고리 정보와는 다르게, 브랜드는 각각의 브랜드에 따라서 특정 시기에 유행이 존재하니 유의미한 정보를 찾을 수 있다 기대해 보았습니다. 하지만 생성된 그래프를 통해 각 브 랜드 카테고리별 제품의 판매 추세와 패턴을 관찰하였으나, 특정 시즌이나 기간에 따른 판매량의 증가나 감소 추이와 제품 간 판매량의 유사성 비교에서 도움이 되는 정보를 얻지 못했습니다.
6. 쇼핑몰 별 판매 양상
# 판매량 이외의 피처 제거
sales_data = data.drop(columns=['ID', '제품', '대분류', '중분류', '소분류', '브랜드'])
sales_data = sales_data.sample(frac=0.1) # 데이터의 10%를 샘플링
# 시각화를 쉽게 하기 위해 데이터프레임을 melt
melted_sales_data = sales_data.melt(id_vars=["쇼핑몰"], var_name="날짜", value_name="판매량")
# '날짜'를 datetime 형식으로 변환
melted_sales_data['날짜'] = pd.to_datetime(melted_sales_data['날짜'])
# 쇼핑몰별 일일 평균 판매량 계산
average_sales_per_day = melted_sales_data.groupby(['쇼핑몰', '날짜']).agg({'판매량':'mean'}).reset_index()
# 시각화
plt.figure(figsize=(14, 8))
for shopping_mall in average_sales_per_day['쇼핑몰'].unique():
mall_data = average_sales_per_day[average_sales_per_day['쇼핑몰'] == shopping_mall]
plt.plot(mall_data['날짜'], mall_data['판매량'], label=shopping_mall)
plt.title('Average Sales per Day by Shopping Mall')
plt.xlabel('Date')
plt.ylabel('Average Sales')
plt.legend()
plt.grid(True)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
※ 결과해석
쇼핑몰에 따라서 판매량 Scale의 차이가 존재함을 볼 수 있습니다. 이는 쇼핑몰 class imbalance에 의해 낮은 비율을 차지하는 쇼핑몰은 공통 패턴 학습에 어려움이 있음을 생각할 수 있습니다. 따라서 이 정보는 Modeling에서 카테고리별 Split과 같은 접근 방법으로 활용할 수 있습니다.
7. 카테고리 구분 없이 랜덤 샘플링 EDA
np.random.seed(0)
date_columns = data.columns[7:]
data = data.sample(frac=0.1) # 데이터의 10%를 샘플링
data_long = data.melt(id_vars=['ID', '제품', '대분류', '중분류', '소분류', '브랜드', '쇼핑몰'],
value_vars=date_columns,
var_name='날짜',
value_name='값')
data_long['날짜'] = pd.to_datetime(data_long['날짜'])
# 분석에서 제외할 특성 목록
skip_features = ['ID', '제품', '대분류', '중분류', '소분류', '브랜드', '쇼핑몰']
sampled_ids = np.random.choice(data_long['ID'].unique(), 7, replace=False)
# 데이터 시각화
for col in data_long.columns:
if np.issubdtype(data_long[col].dtype, np.number) and col not in skip_features:
for num in sampled_ids:
subset = data_long[data_long['ID'] == num]
plt.figure(figsize=(15, 5))
plt.plot(subset['날짜'], subset[col])
plt.xlabel('Date')
plt.xticks(rotation=45)
plt.ylabel("Demand")
plt.title(f"ID: {num}")
plt.show()



※ 결과해석
무작위로 구분 없이 생서한 그래프들처럼 대분류, 중분류, 소분류, 브랜드별 동일 그룹내에서 제품들간의 유사성이 보이지 않습니다. 지금까지의 EDA 결과로는 해당 정보는 필요없어 보입니다. 따라서 이후에 모델링에서 제외시키는게 학습 측면에서 좋아 보인다 판단할 수 있습니다.
8. 0과 0이 아닌 판매량 날 빈도 bar plot
data = pd.read_csv("train.csv")
binary_data = data.iloc[:, 7:].applymap(lambda x: 0 if x != 0 else 1).values.flatten()
percentage_data = (pd.Series(binary_data).value_counts(normalize=True) * 100)
plt.figure(figsize=(8, 6))
barplot = sns.barplot(x=percentage_data.index, y=percentage_data.values)
plt.title('Percentage of Zero vs Non-Zero Values Across All Dates')
plt.xlabel('Value')
plt.ylabel('Percentage')
plt.xticks([0, 1], ['Zero', 'Non-Zero'])
for bar in barplot.patches:
barplot.annotate(format(bar.get_height(), '.2f') + '%',
(bar.get_x() + bar.get_width() / 2,
bar.get_height()), ha='center', va='center',
size=10, xytext=(0, 8),
textcoords='offset points')
plt.show()
※ 결과해석
생성된 bar plot을 통해 판매 데이터 내에서 판매가 발생하지 않은 날과 발생한 날의 비율을 시각적으로 이해할 수 있습니다.
이 막대 그래프는 전체 판매 데이터에서 0의 값(판매가 일어나지 않은 날)과 0이 아닌 값(판매가 일어난 날)의 비율을 시각적으로 보여줍니다. "Zero"와 "Non-Zero'로 표시된 막대를 통해, 특정 기간 동안 제품의 판매가 발생하지 않은 날들과 발생한 날들의 비율을 확인할 수 있습니다.
9. 중복된 제품 식별
# 제품별 샘플 수를 집계
product_sample_counts = data['제품'].value_counts()
# 동일 제품 수가 1보다 큰 샘플들만 필터링
multiple_samples = product_sample_counts[product_sample_counts > 1]
print("동일한 제품을 가진 샘플 개수:")
print(len(multiple_samples))동일한 제품을 가진 샘플 개수:
1084
※ 결과해석
이 과정을 통해 도출된 중복된 제품의 개수는 데이터의 중복 처리 방법을 결정하는 데 중요한 기준이 됩니다. 예를 들어, 중복 제품 데이터의 처리 (예: 중복 제거, 데이터 병합 등)에 활용할 수 있습니다. 먼저 제거나 병합 을 하기 전에, 다음 스텝에서 동일한 제품명을 병합해서 확인하겠습니다.
10. 중복된 제품 샘플 비교
samples = ["SAMPLE_00007", "SAMPLE_00011"]
for sample_id in samples:
sample_data = data[data['ID'] == sample_id]
sales_data = sample_data.iloc[:, 7:]
sales_data = sales_data.sum(axis=0)
sales_data.index = pd.to_datetime(sales_data.index)
# 판매량 시각화
plt.figure(figsize=(14, 7))
plt.plot(sales_data.index, sales_data.values, color='black')
plt.title(f'Sample ID: {sample_id}')
plt.xlabel('날짜')
plt.ylabel('판매량')
plt.grid(True)
plt.show()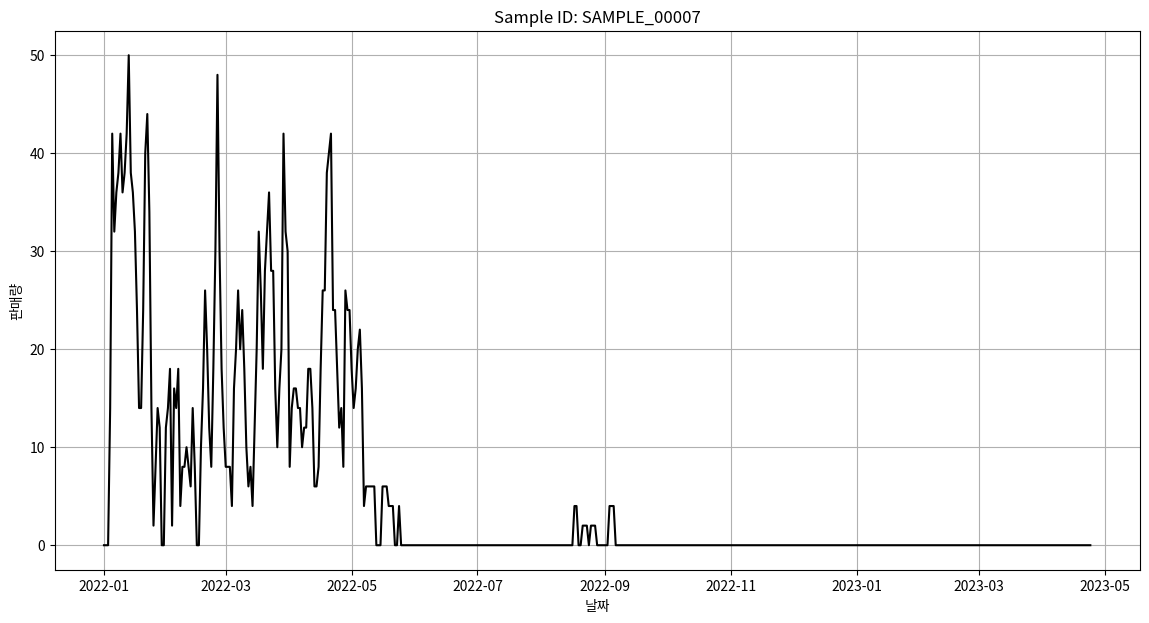
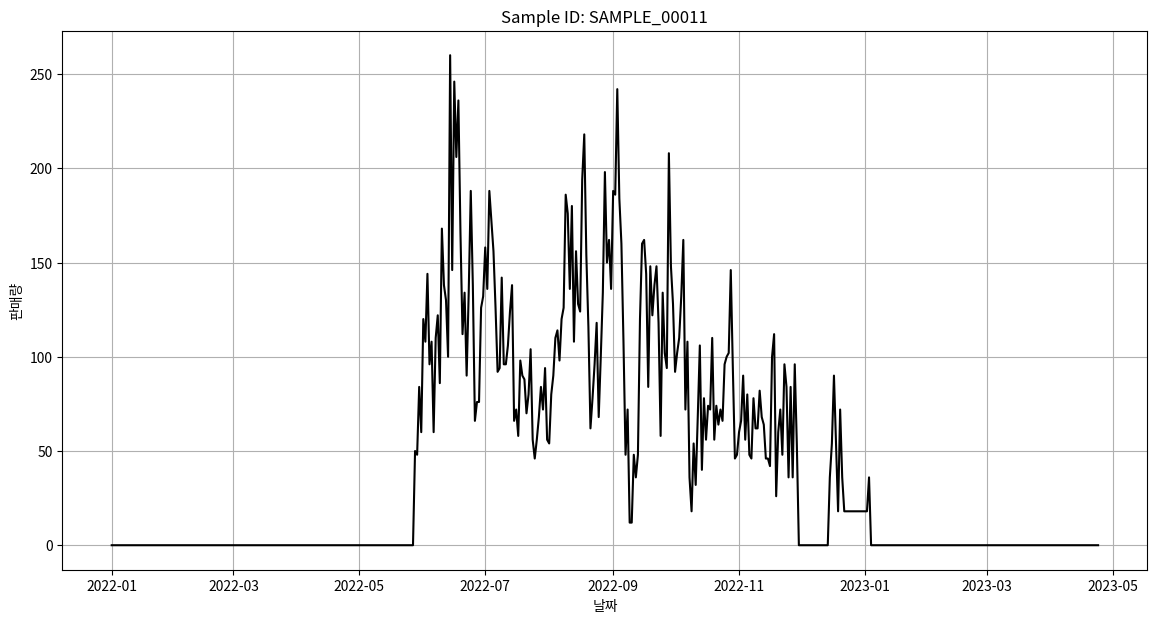
※ 결과해석
중복된 제품명을 가진 두 샘플의 시각화를 해보았습니다. 이 두 샘플이 유사한 추세와 판매량을 보이는 것 같습니다. 다음 단계에서는 이 두 샘플을 병합하여 한 번에 확인해 볼 예정입니다.
11. 중복된 제품 샘플 시각화
specific_samples = data[data['ID'].isin(["SAMPLE_00007", "SAMPLE_00011"])]
plt.figure(figsize=(14, 7))
colors = ['blue', 'red']
for sample, color in zip(specific_samples['ID'], colors):
sales_data = specific_samples[specific_samples['ID'] == sample].iloc[:, 7:].sum()
sales_data.index = pd.to_datetime(sales_data.index)
plt.plot(sales_data, label=sample, color=color)
plt.title('날짜별 판매량 - SAMPLE_00007과 SAMPLE_00011 (색깔 구분)')
plt.xlabel('날짜')
plt.ylabel('판매량')
plt.legend()
plt.grid(True)
plt.show()
※ 결과해석
중복된 제품명을 가진 데이터의 판매량을 병합하여 시각화했더니, 시간에 따라 판매량이 하나의 샘플처럼 표시되었습니다. 이 결과를 보고 중복된 제품명을 가진 샘플들의 데이터를 통합하는 아이디어로 발전시킬 수 있습니다.