머신러닝/머신러닝: 실전 프로젝트 학습
신용카드 사용자 연체 예측 프로젝트 2 : 범주형 변수 EDA 및 결측값 대체
qordnswnd123
2025. 1. 4. 16:33
1. 데이터 로드
import pandas as pd
import numpy as np
# 시각화 라이브러리
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
fe = fm.FontEntry(fname = 'MaruBuri-Regular.otf', name = 'MaruBuri')
fm.fontManager.ttflist.insert(0, fe)
plt.rc('font', family='MaruBuri')
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
train.head(5)
2. credit별 범주형 변수의 분포 확인
# 각 credit별 데이터프레임을 정의합니다.
train_0 = train[train['credit']==0.0]
train_1 = train[train['credit']==1.0]
train_2 = train[train['credit']==2.0]
# 각 credit별 데이터프레임 리스트를 정의합니다.
train_dfs = [train_0, train_1, train_2]
title = ['credit 0', 'credit 1', 'credit 2']
# credit별 범주형 변수의 분포를 확인하기 위해 함수를 정의합니다.
def category_countplot(column):
"""
category_countplot 함수에 입력할 수 있는 범주형 변수는 다음과 같습니다.
'gender', 'car', 'reality', 'income_type',
'edu_type', 'family_type', 'house_type',
'flag_mobil', 'work_phone', 'phone', 'email'
"""
fig, ax = plt.subplots(1, 3, figsize=(16, 6))
for i in range(len(title)):
sns.countplot(x=column, data=train_dfs[i], ax=ax[i], order=train_dfs[i][column].value_counts().index)
ax[i].tick_params(labelsize=12, rotation=50)
ax[i].set_title(title[i])
ax[i].set_ylabel('count')
plt.tight_layout()
plt.show()
return ax
# category_countplot 함수에 확인하고자 하는 범주형 변수를 입력하여 credit별 데이터 분포를 확인해보세요.
col_name = 'gender'
result_countplot = category_countplot(col_name)
3. 적은 등장 빈도를 가진 값 분석
# income_type과 edu_type의 각 범주에 대한 빈도를 계산하고, 각 범주명과 해당 빈도를 반환
income_type_counts = train['income_type'].value_counts()
edu_type_counts = train['edu_type'].value_counts()
# income_type과 edu_type에서 가장 빈도가 낮은 범주를 가져옴
last_income_type = income_type_counts.index[-1]
last_edu_type = edu_type_counts.index[-1]
# 가장 빈도가 낮은 income_type 범주에 대한 income_total의 평균과 중앙값 계산
last_income_type_mean = train[train['income_type'] == last_income_type]['income_total'].mean()
last_income_type_median = train[train['income_type'] == last_income_type]['income_total'].median()
# 가장 빈도가 낮은 edu_type 범주에 대한 income_total의 평균과 중앙값 계산
last_edu_type_mean = train[train['edu_type'] == last_edu_type]['income_total'].mean()
last_edu_type_median = train[train['edu_type'] == last_edu_type]['income_total'].median()
print(f"income_total의 평균은 {train['income_total'].mean()}, 중앙값은 {train['income_total'].median()}입니다.")
print('-'*60)
print(f'{last_income_type}의 income_total 평균값은 {last_income_type_mean}, income_total 중앙값은 {last_income_type_median}입니다.')
print(f'{last_edu_type}의 income_total 평균값은 {last_edu_type_mean}, income_total 중앙값은 {last_edu_type_median}입니다.')income_total의 평균은 187306.52449257285, 중앙값은 157500.0입니다.
------------------------------------------------------------
Student의 income_total 평균값은 149142.85714285713, income_total 중앙값은 171000.0입니다.
Academic degree의 income_total 평균값은 241630.4347826087, income_total 중앙값은 270000.0입니다.4. credit 별 job_type 분포 시각화
# job_type 칼럼의 결측값을 문자열 nan으로 채움
train['job_type'] = train['job_type'].fillna('nan')
test['job_type'] = test['job_type'].fillna('nan')
# 데이터셋 내에서 어떤 고유한 신용 등급들이 있는지 확인
credits = train['credit'].unique()
# 각 credit 값별로 job_type의 분포를 시각화
fig, axes = plt.subplots(len(credits), 1, figsize=(15, 5*len(credits)))
for i, credit in enumerate(credits):
job_type_credit = train[train['credit'] == credit]['job_type'].value_counts()
# 각 신용 등급별로 job_type의 분포를 막대그래프로 시각화
job_type_credit.plot(kind='bar', ax=axes[i])
axes[i].set_title(f'job_type 분포 (credit: {credit})', fontsize=13)
axes[i].set_xlabel('job_type', fontsize=11)
axes[i].set_ylabel('number', fontsize=11)
axes[i].set_xticklabels(labels=job_type_credit.index, rotation=45)
plt.tight_layout()
plt.show()
5. job_type의 결측값 및 income_type에 따른 분포 분석
# 'job_type' 칼럼의 값이 'nan'인 경우에 해당하는 'income_type'의 분포를 확인합니다.
print('job_type가 nan인 income_type 빈도 확인')
print(train[train['job_type'] == 'nan']['income_type'].value_counts())
print('-'*40)
# job_type에서 등장빈도가 낮은 고유값의 비율을 확인하기 위해 num_freq_low 값을 조절합니다.
# num_freq_low는 등장 빈도가 낮은 job_type 고유값의 개수를 의미합니다.
num_freq_low = 3
low_freq_sum = train['job_type'].value_counts()[-num_freq_low:].sum()
print(f'하위 {num_freq_low} 개의 고유값의 등장빈도는 전체 데이터의 {low_freq_sum / len(train) * 100}% 입니다.')job_type가 nan인 income_type 빈도 확인
Pensioner 4440
Working 2312
Commercial associate 1026
State servant 392
Student 1
Name: income_type, dtype: int64
----------------------------------------
하위 3 개의 고유값의 등장빈도는 전체 데이터의 0.6274331934837661% 입니다.
6. 연금 수령자의 나이 분포 시각화 및 결측값 일부 대체
# 음수로 되어 있는 일자 관련 피처들을 양수로 변환
minus_col = ['days_birth', 'days_employed', 'begin_month']
for i in minus_col:
train[i] = -train[i]
test[i] = -test[i]
# 나이 피처 생성: 출생 일자를 이용하여 나이 계산
train['age'] = train['days_birth'] // 365
test['age'] = test['days_birth'] // 365
# 연금 수령자의 나이 분포를 시각화
pension_age = train[train['income_type'] == 'Pensioner']['age'].value_counts().sort_index()
plt.figure(figsize = (12,8))
sns.barplot(x = pension_age.index, y = pension_age.values)
# 연금 수령 빈도가 높은 연령 구간 표시
plt.axvspan(25, 37, color='red', alpha=0.2)
plt.show()
# job_type의 결측값 개수 출력
print('결측값 대체 전 job_type의 결측값의 수는 ', len(train[train['job_type'] == 'nan']), '개 입니다.')
# 연금 수령자(Pensioner)의 job_type을 'No job'으로 대체
train.loc[(train['job_type'] == 'nan') & (train['income_type'] == 'Pensioner'), 'job_type'] = 'No job'
test.loc[(test['job_type'] == 'nan') & (test['income_type'] == 'Pensioner'), 'job_type'] = 'No job'
# 결측치 대체 후 job_type의 결측값 개수 출력
print('결측값 대체 후 job_type의 결측값의 수는 ',len(train[train['job_type'] == 'nan']), '개 입니다.')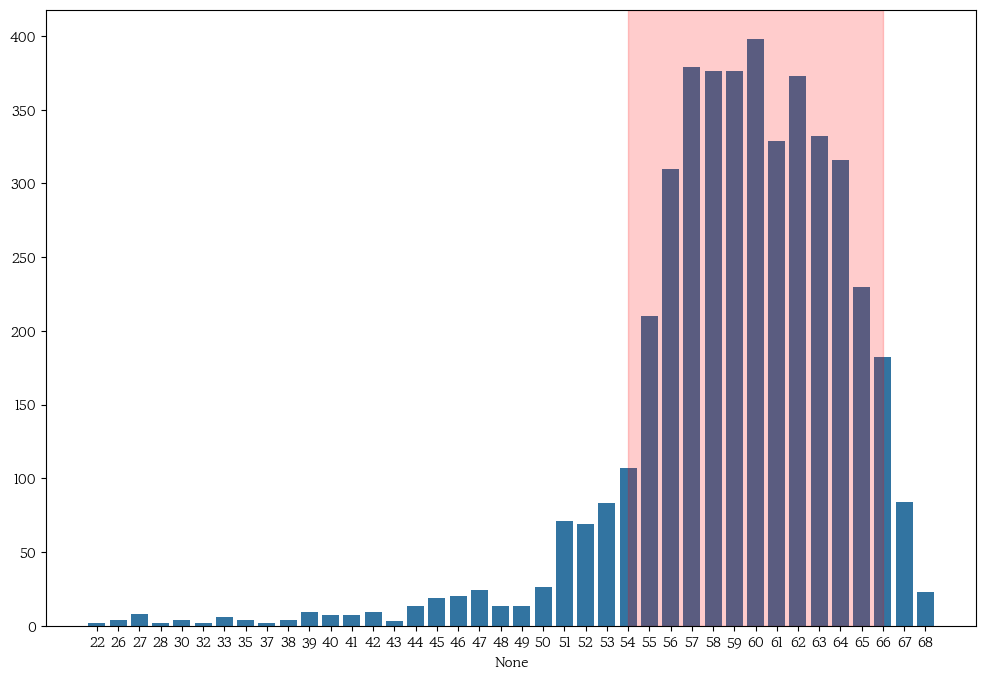
결측값 대체 전 job_type의 결측값의 수는 8171 개 입니다.
결측값 대체 후 job_type의 결측값의 수는 3731 개 입니다.
7. 등장 빈도가 낮은 job_type 배제 후 평균 income_total 값을 활용한 결측치 대체
# 'job_type' 결측값의 수를 확인합니다.
print('결측값 대체 전 job_type의 결측값의 수는 ',len(train[train['job_type'] == 'nan']), '개 입니다.')
# 등장 빈도가 낮은 job_type을 배제하기 위한 기준 값을 n으로 설정합니다.
n = 3
# 'job_type'의 각 범주별 등장 빈도를 확인합니다.
job_type_counts = train['job_type'].value_counts()
# 등장 빈도가 낮은 하위 n개의 'job_type' 범주를 선택합니다.
exclude_job_types = job_type_counts.tail(n).index.tolist()
# 결측치와 등장빈도가 낮은 job_type을 제외하고 각 job_type에 대해 'income_total'의 평균을 계산합니다.
mean_values = train[(train['job_type'] != 'nan') & (~train['job_type'].isin(exclude_job_types))].groupby('job_type')['income_total'].mean()
# 'job_type' 값이 'nan'인 각 행에 대해 반복합니다.
for idx, row in train[train['job_type'] == 'nan'].iterrows():
# 각 job_type의 평균값과의 차이 계산
differences = abs(mean_values - row['income_total'])
# 차이가 가장 작은 job_type을 선택합니다.
closest_job_type = differences.idxmin()
# 현재 행의 'job_type' 값을 가장 가까운 job_type으로 대체합니다.
train.at[idx, 'job_type'] = closest_job_type
# 대체 후 'job_type'의 결측값 수를 다시 확인합니다.
print('결측값 대체 후 job_type의 결측값의 수는 ',len(train[train['job_type'] == 'nan']), '개 입니다.')결측값 대체 전 job_type의 결측값의 수는 3731 개 입니다.
결측값 대체 후 job_type의 결측값의 수는 0 개 입니다.8. test 데이터에 등장 빈도가 낮은 job_type 배제 후 평균 income_total 값을 활용한 결측치 대체
# train 데이터에서 얻은 mean_values를 사용하여 test 데이터의 'job_type' 결측값을 대체합니다.
for idx, row in test[test['job_type'] == 'nan'].iterrows():
# 각 job_type의 평균값과의 차이 계산
# 데이터 누수(Data Leakage) 방지를 위해 train 데이터의 통계값을 사용합니다.
differences = abs(mean_values - row['income_total'])
# 차이가 가장 작은 job_type을 선택합니다.
closest_job_type = differences.idxmin()
# 현재 행의 'job_type' 값을 가장 가까운 job_type으로 대체합니다.
test.at[idx, 'job_type'] = closest_job_type
# 대체 후 test 데이터의 'job_type' 결측값 수를 확인합니다.
print('test 데이터의 결측값 대체 후 job_type의 결측값의 수는 ',len(test[test['job_type'] == 'nan']), '개 입니다.')test 데이터의 결측값 대체 후 job_type의 결측값의 수는 0 개 입니다.