머신러닝/머신러닝: 실전 프로젝트 학습
아파트 경매 가격 예측 프로젝트 5 : 단순 회귀 분석
qordnswnd123
2025. 1. 8. 14:58
1. 데이터 로드
import pandas as pd
train = pd.read_csv('train.csv')
result = pd.read_csv('Auction_result.csv')
2. 데이터 전처리
# year 피처 생성 및 날짜 피처 제거
train['Final_auction_date'] = pd.to_datetime(train['Final_auction_date'], errors = 'ignore')
train['year'] = train['Final_auction_date'].dt.year
date_col = ['Appraisal_date', 'First_auction_date', 'Final_auction_date', 'Preserve_regist_date', 'Close_date']
train = train.drop(date_col, axis= 1)
# 최빈값으로 결측값 보완
addr_freq = train['addr_bunji1'].value_counts().index[0]
road_freq = train['road_bunji1'].value_counts().index[0]
train['addr_bunji1'] = train['addr_bunji1'].fillna(addr_freq)
train['road_bunji1'] = train['road_bunji1'].fillna(road_freq)
# 결측값이 많은 피처 제거
much_null = ['addr_li', 'addr_bunji2', 'Specific', 'road_bunji2']
train = train.drop(much_null, axis = 1)
# Target을 제외하고 상관계수가 높았던 피처 제거
highcorr_col = ['Total_land_real_area', 'Total_land_auction_area', 'Total_building_area', 'Total_building_auction_area']
train = train.drop(highcorr_col, axis =1)
# 데이터 분석 과정에서 제거하기로 결정한 피처 제거
drop_list = ['Close_result', 'Final_result', 'addr_dong', 'addr_etc', 'road_name', 'Appraisal_company', 'Creditor', 'addr_si']
train = train.drop(drop_list, axis = 1)
3. 두 데이터를 활용한 파생변수 생성 및 데이터 결합
# result_year 변수 생성 및 2014년 이후 데이터만 사용
result['result_year'] = pd.to_datetime(result['Auction_date'], errors = 'ignore').dt.year
result = result[result['result_year'] >= 2014]
# 마지막 데이터 추출
need_merge = result[['Auction_key', 'Auction_results']].drop_duplicates(subset = 'Auction_key', keep = 'last')
need_merge = need_merge.reset_index(drop = True)
# 감정가 최솟값 결합
appraisal_min = result.groupby('Auction_key')['Appraisal_price'].min()
need_merge['appraisal_min'] = appraisal_min.values
# 최저매각가격 최솟값 결합
sales_min = result.groupby('Auction_key')['Minimum_sales_price'].min()
need_merge['sales_min'] = sales_min.values
# 경매횟수의 최대값 가져오기
max_seq = result.groupby('Auction_key')['Auction_seq'].max()
need_merge['max_seq'] = max_seq.values
# 경매결과가 유찰인 횟수 가져오기
failed_auction = result[result['Auction_results'] == '유찰']
auction_count = failed_auction.groupby('Auction_key')['Auction_results'].count()
auction_result = need_merge.join(auction_count, on = 'Auction_key', how = 'left', lsuffix = '_left', rsuffix = '_right')
# auction_results_right 결측치 보완
null_indice = auction_result[auction_result['Auction_results_right'].isnull()].index
auction_result.loc[null_indice, 'Auction_results_right'] = 0
# 증감률 피처 생성
last_price = result.groupby('Auction_key')['Minimum_sales_price'].min().values
first_price = result.groupby('Auction_key')['Minimum_sales_price'].max().values
auction_result['change_rate'] = (last_price - first_price) / first_price * 100
# 데이터 결합
train_result = train.merge(auction_result, on = 'Auction_key', how = 'left')
4. 원 핫 인코딩
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(sparse_output=False)
onehot_bid = ohe.fit_transform(train_result[['Bid_class']])
onehot_frame = pd.DataFrame(onehot_bid, columns = ohe.categories_[0])
train_result = pd.concat([train_result, onehot_frame], axis = 1)
train_result = train_result.drop(['Bid_class', '일괄'], axis = 1)
5. 라벨 인코딩
from sklearn.preprocessing import LabelEncoder
label_col = ['Auction_class', 'addr_do', 'addr_san', 'Share_auction_YorN', 'Auction_results_left', 'Apartment_usage']
for label in label_col:
le = LabelEncoder()
train_result[label] = le.fit_transform(train_result[label])
6. 독립변수, 종속변수 설정 및 데이터셋 분리
from sklearn.model_selection import train_test_split
train_x = train_result.drop(['Hammer_price', 'Auction_key'], axis = 1)
train_y = train_result['Hammer_price']
x_train, x_valid, y_train, y_valid = train_test_split(train_x, train_y, test_size=0.3, random_state=42)
7. 메모리 확보
이 코드는 불필요한 데이터프레임을 삭제하고, 메모리를 해제하기 위해 사용합니다.
del 키워드를 사용하여 변수를 삭제하고, gc.collect() 함수를 호출하여 가비지 컬렉션(Garbage Collection)을 수행합니다.
이 과정에서 메모리에서 더 이상 사용되지 않는 객체들을 정리함으로써 메모리를 확보할 수 있습니다.
import gc
del need_merge
del auction_result
del train_result
gc.collect()178
8. 단순 회귀 모델 학습 및 검증점수 확인
OLS(Ordinary Least Squares)는 잔차제곱합 (RSS: Residual Sum of Squares)을 최소화하는 방식입니다.
mean_squared_error 함수를 사용하면 검증 데이터에 대한 RMSE 값을 얻을 수 있습니다.
mean_squared_error() 함수에 squared 매개변수의 값을 False로 설정하면 RMSE가 계산되지만, True로 설정하면 MSE가 계산됩니다.
import statsmodels.api as sm
from sklearn.metrics import mean_squared_error
ols = sm.OLS(y_train, x_train)
results = ols.fit()
valid_pred = results.predict(x_valid)
check_mse = mean_squared_error(y_valid, valid_pred, squared = False)
check_mse118622727.13642745
9. 단순 회귀 분석 결과 확인
[선형회귀 분석의 기본 4 요소]
- 선형성: 예측하고자 하는 종속변수 y와 독립변수 x 간에 선형성을 만족하는 특성을 의미합니다.
만약, 내가 가지고 있는 변수 중 일부가 선형성을 만족하지 않는다면?- 다른 새로운 변수를 추가한다.
- 로그, 제곱, 루트 등 변수 변환을 취한다.
- 아예 선형성을 만족하지 않는 변수를 제거한다. 등 여러 가지 방법이 있습니다.
- 독립성: 독립변수 x 간에 상관관계가 없이 독립성을 만족하는 특성을 의미합니다. ("다중 공선성에서 해당")
만약 서로 상관관계가 있는 독립변수들이 여러 개 들어가면 회귀분석 결과는 유의미하지 않은 결과를 나타내게 됩니다.
때문에 독립변수 간에 서로 상관관계가 있다면 이를 제거해 주어야 합니다.
이를 위해 다중공선성을 일으키는 변수를 제거하거나, 이중에서도 모아서 다른 변수로 치환시키는 방법이 있습니다. - 등분산성: 잔차의 분산이 독립변수에 관계없이 일정함을 의미합니다. (잔차의 패턴이 고르지 못함)
- 정규성: 잔차가 정규분포를 따르도록 이루는 특성을 의미합니다. (잔차가 종모양을 따르는지 여부)
<요약>
4가지 기본 가정을 만족해야 유의미한 회귀모델이 나옵니다.
이를 위한 가장 좋은 방법은 4가지 기본 가정을 위배한 변수들을 제거하는 것입니다.
results.summary()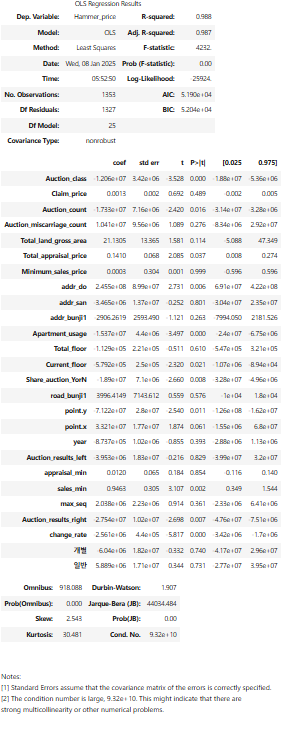
※ 결과 해석
- 모델의 설명력을 나타내는 지표인 R-squared와 Adj.R-squared가 약 0.980으로 회귀 모델이 종속 변수의 변동성을 약 98.7% 정도 설명할 수 있습니다.
즉, 모델이 독립 변수들로 종속 변수의 변동을 매우 잘 설명하고 있다는 것을 나타냅니다.
높은 R-squared 값은 모델의 설명력이 높다는 것을 의미하며, 예측 정확도가 상당히 높다고 해석할 수 있습니다. - 회귀 모델의 전체적인 유의성을 검증하는 지표인 F-statistic이 423201이고,
관련된 p-value가 0.000로 회귀 모델의 유의성이 통계적으로 매우 높은 의미입니다.
즉, 회귀 모델이 독립 변수들을 포함하는 데에 유의한 이유가 있다는 것을 의미합니다. - 잔차의 분포를 나타내는 지표인 Kurtosis가 30.48입니다.이 값은 종속 변수의 정규분포와의 가까움을 의미하는데, 30.48이 나타났으므로 정규분포보다 훨씬 뾰족한 분포를 가지고 있을 수 있습니다.
따라서, 이러한 결과는 잔차가 너무 뾰족한 분포를 가지고 있으며, 이는 회귀 모델의 잔차가 정규분포 가정을 만족하지 못할 수 있다는 것을 시사합니다.