시계열 교차검증 (TimeSeries Split & Sliding Window Split)
1. 시계열 교차 검증의 필요성 및 종류
시계열 데이터는 시간 의존성, 계절성, 추세, 비정상성 등의 특성을 가지므로, 이러한 특성을 반영한 검증 방법이 필요합니다. 시계열 데이터에서는 시간 순서를 유지한면서 데이터를 분할하는 교차 검증 방법이 필요합니다. 이를 통해 모델이 시간 의존성, 계절성, 추세, 비정상성을 모두 반영하여 학습할 수 있습니다. 이는 모델의 예측 성능을 더 정확하게 평가하고, 실제 상황에서 더 잘 동작하는 모델을 만들기 위해 필수적입니다.
※ 시계열 교차 검증 방법의 종류
1) 타임시리즈 분할 교차 검증

타임시리즈 분할 교차 검증은 초기의 작은 훈련 세트로 시작하여, 이후 각 단계마다 훈련 세트의 크기를 확장해나가는 방식입니다. 이 방법은 시간이 지남에 따라 점점 더 많은 과거 데이터를 훈련 세트에 포함시킵니다. 검증 세트는 고정된 크기를 유지하면서 이동합니다.
- 장점: 더 많은 데이터가 훈련에 사용되면서 모델의 성능이 향상될 수 있습니다.
- 단점: 처음 몇 번의 검증에서는 훈련 데이터가 적기 때문에 모델의 성능이 불안정할 수 있습니 다.
인공지능 대회 혹은 실전 연구 프로젝트에서 시계열 데이터를 다룰 때, 특히 데이터셋이 충분히 크지 않은 경우에 모델의 일반화 성능을 평가하기 위하여 필수적으로 시계열 교차검증을 해야 합니다.
2) 슬라이딩 윈도우 검증

슬라이딩 윈도우 검증은 고정된 크기의 윈도우를 사용하여 데이터셋을 반복적으로 훈련과 테스트 세트로 나누는 방법입니다. 윈도우는 데이터셋을 따라 일정 간격으로 이동하며, 각 윈도우마 다 모델을 훈련시키고 평가합니다.
- 장점: 모든 데이터가 여러 번 훈련에 사용될 수 있어 데이터 활용도가 높습니다.
- 단점: 연속적인 데이터 포인트가 많으면 계산 비용이 높아질 수 있습니다.
2. 시계열 교차 검증의 구현 및 적용 방법
1) 공통 함수 선언
import numpy as np
import pandas as pd
import torch
import random
import torch.nn as nn
from sklearn.model_selection import TimeSeriesSplit
import matplotlib.pyplot as plt
# device 설정
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 난수 시드 설정
def set_seed(seed_value):
random.seed(seed_value) # 파이썬 난수 생성기
np.random.seed(seed_value) # Numpy 난수 생성기
torch.manual_seed(seed_value) # PyTorch 난수 생성기
# CUDA 환경에 대한 시드 설정 (GPU 사용 시)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed_value)
torch.cuda.manual_seed_all(seed_value)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# 시퀀스 데이터 생성 함수
def build_sequence_dataset(df, taget, seq_length):
dataX = []
dataY = []
for i in range(0, len(df) - seq_length):
_x = df.iloc[i:i + seq_length].values # 시퀀스 데이터
_y = df.iloc[i + seq_length][taget] # 다음 포인트의 기온을 레이블로 사용
dataX.append(_x)
dataY.append(_y)
return np.array(dataX), np.array(dataY)
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super(LSTMModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size) # 출력 크기 조정을 위한 선형 레이어
def forward(self, x):
batch_size = x.size(0)
h0, c0 = self.init_hidden(batch_size, x.device)
out, _ = self.lstm(x, (h0, c0))
out = self.fc(out[:, -1, :]) # 마지막 타임 스텝의 출력만 사용
return out
def init_hidden(self, batch_size, device):
h0 = torch.zeros(self.num_layers, batch_size, self.hidden_size).to(device)
c0 = torch.zeros(self.num_layers, batch_size, self.hidden_size).to(device)
return h0, c0
def train(model, train_loader, optimizer, criterion):
model.train() # 모델을 학습 모드로 설정
total_loss = 0
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(train_loader)
def validate_model(model, test_loader, criterion):
model.eval() # 모델을 평가 모드로 설정
total_loss = 0
actuals = []
predictions = []
with torch.no_grad(): # 그라디언트 계산을 비활성화
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
loss = criterion(output, target)
total_loss += loss.item()
# 예측값과 실제값을 리스트에 저장
actuals.extend(target.squeeze(1).tolist())
predictions.extend(output.squeeze(1).tolist())
# 손실 계산
avg_loss = total_loss / len(test_loader)
return avg_loss, actuals, predictions
2) 데이터 로드
##########################################################
# 데이터 로드
##########################################################
df_weather_org = pd.read_csv('sample_weather_data.csv')
features = ['humidity','rainfall','wspeed','temperature']
display(f"데이터 길이 : {len(df_weather_org)} ")
display(df_weather_org.head())
3. TimeSeriesSplit 교차 검증
1) TimeSeriesSplit을 사용하여 기본 교차 검증 폴드 분할
scikit-learn의 TimeSeriesSplit을 이용하여 시계열 데이터를 교차 검증 폴드로 분할해 보겠습니다.
TimeSeriesSplit은 시계열 데이터의 순서를 유지하면서 데이터를 훈련 세트와 테스트 세트로 나누는 역할을 수행하는 scikit-learn의 모듈입니다.
※ Scikit-learn의 TimeSeriesSplit 클래스와 매개 변수
sklearn.model_selection 모듈에 포함되어 있으며, 시 계열 데이터의 교차 검증을 수행하기 위해 사용합니다.
- n_splits: (기본값: 5) 데이터셋을 나눌 분할 수를 지정 합니다. 이 값은 훈련/테스트 세트 쌍의 수를 의미합니 다.
- max_train_size: (기본값: None) 훈련 세트의 최대 크 기를 지정합니다. 이 값을 설정하면 훈련 세트의 크기 가 지정된 값으로 제한됩니다.
- test_size: (기본값: None) 테스트 세트의 크기를 지정 합니다. 이 값을 설정하지 않으면 테스트 세트의 크기 는 자동으로 결정됩니다.
- gap: (기본값: 0) 훈련 세트와 테스트 세트 사이의 간 격을 지정합니다. 이 값은 훈련 세트의 마지막 데이터 포인트와 테스트 세트의 첫 번째 데이터 포인트 사이 의 간격을 의미합니다.
from sklearn.model_selection import TimeSeriesSplit
num_splits = 3 # 교차검증 분할 수
tscv = TimeSeriesSplit(n_splits=num_splits)
# 예제 데이터 생성
data = np.arange(20) # 0부터 19까지의 숫자 배열
print("전체 데이터:", data)
# 데이터 분할
for fold, (train_index, test_index) in enumerate(tscv.split(data), start=1):
print(f"Fold {fold}")
print(f"Train data: {data[train_index]}")
print(f"Test data: {data[test_index]}")
print("-" * 50)
fold +=1전체 데이터: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]
Fold 1
Train data: [0 1 2 3 4]
Test data: [5 6 7 8 9]
--------------------------------------------------
Fold 2
Train data: [0 1 2 3 4 5 6 7 8 9]
Test data: [10 11 12 13 14]
--------------------------------------------------
Fold 3
Train data: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14]
Test data: [15 16 17 18 19]
--------------------------------------------------
※ 결과 해석
시계열 데이터를 시간 순서를 유지하면서 여러개의 훈련 세트와 테스트 세트로 분할하는 방법을 보여줍니다.
각 분할마다 훈련 데이터의 크기가 점점 커지며, 테스트 데이터는 고정된 크기로 유지됩니다.
2) TimeSeriesSplit을 사용하여 테스트 사이즈를 명시적으로 설정하고 교차 검증 폴드 분할하기
# 교차검증 분할 수와 테스트 세트 크기 설정
num_splits = 2 # 3으로 설정할 경우 에러 발생
num_test_fold = 7
tscv = TimeSeriesSplit(n_splits=num_splits, test_size=num_test_fold)
# 예제 데이터 생성
data = np.arange(20) # 0부터 9까지의 숫자 배열
print("전체 데이터:", data)
# 데이터 분할
for fold, (train_index, test_index) in enumerate(tscv.split(data), start=1):
print(f"Fold {fold}")
print(f"Train data: {data[train_index]}")
print(f"Test data: {data[test_index]}")
print("-" * 50)전체 데이터: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]
Fold 1
Train data: [0 1 2 3 4 5]
Test data: [ 6 7 8 9 10 11 12]
--------------------------------------------------
Fold 2
Train data: [ 0 1 2 3 4 5 6 7 8 9 10 11 12]
Test data: [13 14 15 16 17 18 19]
--------------------------------------------------
3) weather 데이터에 대한 시퀀스 데이터 생성 및 TimeSeriesSplit을 이용한 폴드 분할하기
df_weather = df_weather_org[features]
target_col = ['temperature']
seq_length = 6
sequence_dataX, sequence_dataY = build_sequence_dataset(df_weather, target_col, seq_length)
print(f"데이터 길이 : {len(df_weather)} ")
print(f"sequence_dataX의 형태(shape) : {sequence_dataX.shape}")
print(f"sequence_dataX의 형태(shape) : {sequence_dataY.shape}")
tscv = TimeSeriesSplit(n_splits=3)
# 데이터 분할
for fold, (train_index, test_index) in enumerate(tscv.split(sequence_dataX), start=1):
print(f"Fold {fold}")
print(f"Train data index: {train_index[0]} ~ {train_index[-1]} ")
print(f"Train data shape: {np.array(sequence_dataX[train_index]).shape}")
print(f"Test data index: {test_index[0]} ~ {test_index[-1]} ")
print(f"Test data shape: {np.array(sequence_dataX[test_index]).shape}")
print("-" * 50)데이터 길이 : 730
sequence_dataX의 형태(shape) : (724, 6, 4)
sequence_dataX의 형태(shape) : (724, 1)
Fold 1
Train data index: 0 ~ 180
Train data shape: (181, 6, 4)
Test data index: 181 ~ 361
Test data shape: (181, 6, 4)
--------------------------------------------------
Fold 2
Train data index: 0 ~ 361
Train data shape: (362, 6, 4)
Test data index: 362 ~ 542
Test data shape: (181, 6, 4)
--------------------------------------------------
Fold 3
Train data index: 0 ~ 542
Train data shape: (543, 6, 4)
Test data index: 543 ~ 723
Test data shape: (181, 6, 4)
--------------------------------------------------
4) TimeSeriesSplit를 적용 통한 폴드 분할 시각화 하기
import matplotlib.pyplot as plt
import numpy as np
df_weather = df_weather_org[features]
# 원래의 actual 데이터 추출
original_actuals = df_weather['temperature'].values
fig, ax = plt.subplots(figsize=(12, 6))
# 원래의 actual 데이터
ax.plot(original_actuals, label='Original Actual Values', color='green')
# 각 폴드의 시작점을 세로 줄로 표시하고, 학습 및 테스트 데이터의 기간을 가로 화살표로 표시
for fold, (train_index, test_index) in enumerate(tscv.split(sequence_dataX), start=1):
print(f"Fold {fold}")
print(f"Train data index: {train_index[0]} ~ {train_index[-1]} ")
print(f"Train data shape: {np.array(sequence_dataX[train_index]).shape}")
print(f"Test data index: {test_index[0]} ~ {test_index[-1]} ")
print(f"Test data shape: {np.array(sequence_dataX[test_index]).shape}")
print("-" * 50)
# 세로 점선으로 폴드 시작점 표시
ax.axvline(x=test_index[0], color='red', linestyle='--', label=f'Fold {fold} Start' if fold == 1 else "")
# 가로 화살표로 학습 데이터 기간 표시 (높이를 폴드별로 다르게 설정)
train_y_pos = original_actuals.max() + 2 + (4 - fold) * 4 # 폴드 순서를 위에서부터 1, 2, 3으로 변경하고 간격을 두 배로 크게 설정
ax.hlines(y=train_y_pos, xmin=train_index[0], xmax=train_index[-1], color='blue', linestyle='-', linewidth=2)
ax.text((train_index[0] + train_index[-1]) / 2, train_y_pos + 0.5, f'Train {fold}', color='blue', ha='center')
# 가로 화살표로 테스트 데이터 기간 표시 (높이를 폴드별로 다르게 설정)
test_y_pos = original_actuals.max() + 2 + (4 - fold) * 4 # 폴드 순서를 위에서부터 1, 2, 3으로 변경하고 간격을 두 배로 크게 설정
ax.hlines(y=test_y_pos, xmin=test_index[0], xmax=test_index[-1], color='orange', linestyle='-', linewidth=2)
ax.text((test_index[0] + test_index[-1]) / 2, test_y_pos + 0.5, f'Test {fold}', color='orange', ha='center')
ax.set_title('Original Actual Values with Fold Start Points and Train/Test Periods')
ax.set_xlabel('Sample Number')
ax.set_ylabel('Temperature')
ax.grid(True)
ax.legend()
plt.show()Fold 1
Train data index: 0 ~ 180
Train data shape: (181, 6, 4)
Test data index: 181 ~ 361
Test data shape: (181, 6, 4)
--------------------------------------------------
Fold 2
Train data index: 0 ~ 361
Train data shape: (362, 6, 4)
Test data index: 362 ~ 542
Test data shape: (181, 6, 4)
--------------------------------------------------
Fold 3
Train data index: 0 ~ 542
Train data shape: (543, 6, 4)
Test data index: 543 ~ 723
Test data shape: (181, 6, 4)
--------------------------------------------------

※ 결과 해석
- 시간 순서 유지: 그래프에서 데이터가 시간 순서대로 분할되는 것을 확인할 수 있습니다. 이는 시계열 데이터의 시간 의존성을 보존합니다.
- 점진적 학습 세트 증가: 각 폴드에서 학습 데이터(파란색 선)의 길이가 점차 늘어나 는 것을 볼 수 있습니다. 이는 모델이 시간이 지남에 따라 더 많은 과거 데이터를 학 습하게 됨을 의미합니다.
- 고정된 테스트 세트 크기: 모든 폴드에서 테스트 데이터(주황색 선)의 길이가 동일 합니다. 이는 일관된 평가 기준을 제공합니다.
- 미래 예측 시뮬레이션: 각 폴드의 테스트 세트는 항상 해당 학습 세트 이후의 기간 을 커버합니다. 이는 실제 예측 상황을 모방하여, 과거 데이터로 미래를 예측하는 구 조를 만듭니다.
이 시각화를 통해 TimeSeriesSplit이 시계열 데이터의 특성을 고려하여 어떻게 데 이터를 분할하는지 직관적으로 이해할 수 있습니다. 이러한 분할 방식은 시간에 따 른 모델의 성능 변화를 관찰하고, 미래 데이터에 대한 예측 능력을 적절히 평가할 수 있게 해줍니다.
5) 학습 및 테스트 시퀀스 데이터 준비와 스케일링
prepare_scaled_sequences 함수는 분할된 각 폴드의 train_index와 test_index 정보를 이용하여 데이터를 처리합니다. 이 과정에서 학습 데이터만을 사용해 스케일 러를 학습(fit)하고, 이를 테스트 데이터에 적용하는 방식을 사용합니다. 그 이유는 시계열 데이터의 특성과 실제 예측 시나리오를 정확히 반영하기 위함입니다.
시계열 교차 검증에서 분할된 폴드는 시간 순서를 따라 train 데이터 다음에 test 데이터가 위치합니다. 여기서 test 데이터는 '미래'의 데이터를 나타냅니다. 만약 train 데이터뿐만 아니라 test 데이터를 포함한 전체 데이터를 스케일링한다면, 이는 실제로는 알 수 없는 미래의 정보를 이용하여 통계적 처리를 하는 것과 같습니다. 이러한 행위를 데이터 누수(data leakage)라고 합니다.
데이터 누수는 모델이 실제 상황에서는 접근할 수 없는 정보를 학습 과정에서 사용하게 만듭니다. 이는 모델의 성능을 과대평가하게 만들고, 실제 예측 상황에서 모델 이 기대만큼의 성능을 내지 못하는 원인이 됩니다. 특히 시계열 데이터에서는 미래의 데이터 분포가 과거와 다를 수 있기 때문에, 이러한 누수 문제가 더욱 중요해집니 다.
따라서 학습 데이터만을 사용해 스케일러를 학습(fit)하고, 이를 테스트 데이터에 적용(transform)하는 방식은 다음과 같은 이점을 제공합니다
- 데이터 누수 방지: 테스트 데이터(미래 데이터)의 정보가 학습 과정에 유입되는 것을 막아, 모델의 공정한 평가를 가능하게 합니다.
- 현실적인 예측 시나리오 모방: 실제 상황에서는 미래 데이터의 분포를 알 수 없으므로, 이 방식은 실제 예측 환경을 더 정확히 시뮬레이션합니다.
- 모델의 일반화 능력 향상: 알려지지 않은 데이터 분포에 대한 모델의 적응력을 테스트함으로써, 더 강건한 모델을 개발할 수 있습니다. 이러한 방식을 통해, 우리는 더 신뢰할 수 있는 모델 평가와 실제 상황에 더 잘 대응할 수 있는 모델을 개발할 수 있 습니다.
from sklearn.preprocessing import StandardScaler
def prepare_scaled_sequences(df, features, target_col, seq_length, train_index, test_index):
df_train = df.iloc[train_index]
train_data_X = df_train[features]
train_data_Y = df_train[target_col]
scaler_x = StandardScaler()
scaler_y = StandardScaler()
train_data_X_scaled = scaler_x.fit_transform(train_data_X)
train_data_Y_scaled = scaler_y.fit_transform(train_data_Y)
df_train_scaled = pd.DataFrame(train_data_X_scaled, columns=features, index=train_data_X.index)
df_train_scaled[target_col] = train_data_Y_scaled
df_test = df.iloc[test_index]
test_data_X = df_test[features]
test_data_Y = df_test[target_col]
test_data_X_scaled = scaler_x.transform(test_data_X)
test_data_Y_scaled = scaler_y.transform(test_data_Y)
df_test_scaled = pd.DataFrame(test_data_X_scaled, columns=features, index=test_data_X.index)
df_test_scaled[target_col] = test_data_Y_scaled
sequence_dataX_train, sequence_dataY_train = build_sequence_dataset(df_train_scaled, target_col, seq_length)
sequence_dataX_test, sequence_dataY_test = build_sequence_dataset(df_test_scaled, target_col, seq_length)
return sequence_dataX_train, sequence_dataY_train, sequence_dataX_test, sequence_dataY_test, (scaler_x, scaler_y)
prepare_scaled_sequences 함수를 사용하여 생성된 시퀀스 데이터와 스케일링 정보를 확인해 보겠습니다.
주요 시퀀스 데이터의 타입, 길이, 그리고 스케일링 인자의 평균과 스케일을 출력합니다.
seq_length = 6
df_weather = df_weather_org[features]
sequence_dataX_train_ex, sequence_dataY_train_ex, \
sequence_dataX_test_ex, sequence_dataY_test_ex, \
(scaler_x, scaler_y) = prepare_scaled_sequences(df_weather, features, target_col, seq_length, train_index, test_index)
display(f"sequence_dataX_train_ex 타입: {type(sequence_dataX_train_ex)}")
display(f"sequence_dataX_train_ex 길이: {len(sequence_dataX_train_ex)}")
display(f"sequence_dataX_train_ex[0] 길이: {len(sequence_dataX_train_ex[0])}")
display(f"sequence_dataY_train_ex 길이: {len(sequence_dataY_train_ex)}")
display(f"sequence_dataX_test_ex[0] 길이: {len(sequence_dataX_test_ex[0])}")
display(f"sequence_dataY_test_ex 길이: {len(sequence_dataY_test_ex)}")
# 주요 scale factor 출력
display(f"scaler_x mean: {scaler_x.mean_}, scale: {scaler_x.scale_}")
display(f"scaler_y mean: {scaler_y.mean_}, scale: {scaler_y.scale_}")
6) 데이터 로더 생성 및 확인
from torch.utils.data import TensorDataset, DataLoader
def create_data_loaders_from_sequences(sequence_dataX_train, sequence_dataY_train,
sequence_dataX_test, sequence_dataY_test,
batch_size):
# 텐서로 데이터 변환
train_X_tensor = torch.tensor(sequence_dataX_train, dtype=torch.float32)
train_Y_tensor = torch.tensor(sequence_dataY_train.reshape(-1, 1), dtype=torch.float32)
test_X_tensor = torch.tensor(sequence_dataX_test, dtype=torch.float32)
test_Y_tensor = torch.tensor(sequence_dataY_test.reshape(-1, 1), dtype=torch.float32)
# TensorDataset 생성
train_dataset = TensorDataset(train_X_tensor, train_Y_tensor)
test_dataset = TensorDataset(test_X_tensor, test_Y_tensor)
# DataLoader 설정
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
return train_loader, test_loader
작성한 함수 create_data_loaders_from_sequences를 이용하여 생성된 DataLoader를 확인해 보겠습니다.
# DataLoader 생성
train_loader_ex, test_loader_ex = create_data_loaders_from_sequences(
sequence_dataX_train_ex, sequence_dataY_train_ex,
sequence_dataX_test_ex, sequence_dataY_test_ex,
batch_size = 32
)
# train_loader 확인
for data, target in train_loader_ex:
display(f"train_loader - 첫 번째 배치 데이터 크기: {data.shape}")
display(f"train_loader - 첫 번째 배치 타겟 크기: {target.shape}")
display(f"train_loader - 첫 번째 배치 데이터 타입: {type(data)}")
break
# test_loader 확인
for data, target in test_loader_ex:
display(f"test_loader - 첫 번째 배치 데이터 크기: {data.shape}")
display(f"test_loader - 첫 번째 배치 타겟 크기: {target.shape}")
display(f"test_loader - 첫 번째 배치 데이터 타입: {type(data)}")
break
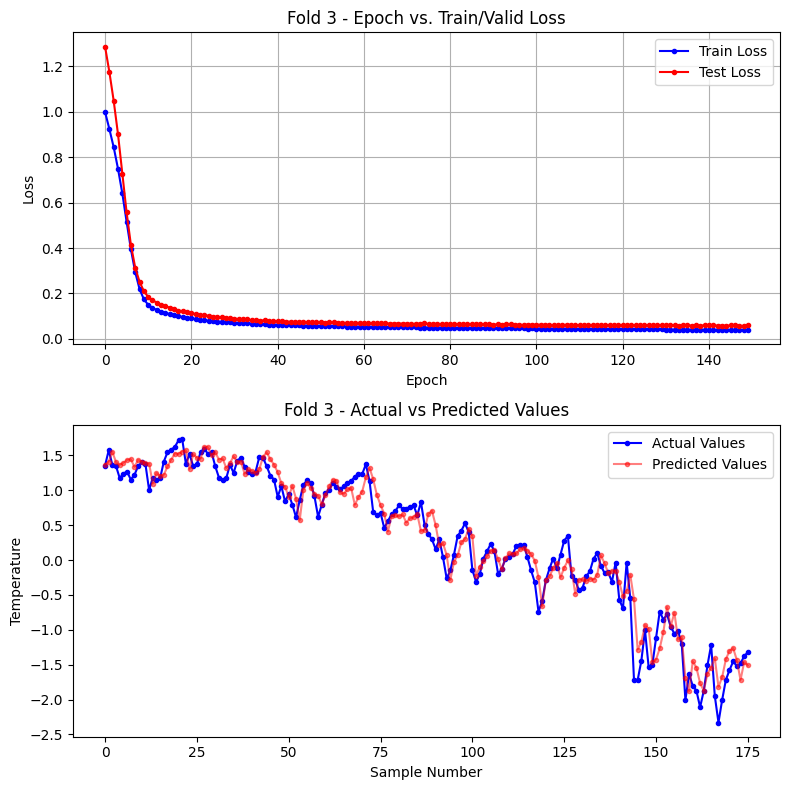
7) 폴드별 실험 결과 시각화를 위한 plot_results 함수 구현
def plot_results(train_loss_lst, test_loss_lst, actuals, predictions, fold=None):
# 서브플롯 생성
fig, axes = plt.subplots(nrows=2, ncols=1, figsize=(8, 8))
if fold is not None:
title_loss = f'Fold {fold} - Epoch vs. Train/Valid Loss'
title_values = f'Fold {fold} - Actual vs Predicted Values'
else:
title_loss = 'Epoch vs. Train/Valid Loss'
title_values = 'Actual vs Predicted Values'
# 첫 번째 그래프: 에포크에 따른 손실
axes[0].plot(train_loss_lst, marker='o', markersize = 3, color='blue', label='Train Loss')
axes[0].plot(test_loss_lst, marker='o', markersize = 3, color='red', label='Test Loss')
axes[0].set_title(title_loss)
axes[0].set_xlabel('Epoch')
axes[0].set_ylabel('Loss')
axes[0].grid(True)
axes[0].legend()
# 두 번째 그래프: 실제값과 예측값
axes[1].plot(actuals, marker='o', markersize = 3,label='Actual Values', color='blue')
axes[1].plot(predictions, marker='o', markersize = 3,label='Predicted Values', color='red', alpha=0.5)
axes[1].set_title(title_values)
axes[1].set_xlabel('Sample Number')
axes[1].set_ylabel('Temperature')
axes[1].legend()
# 전체 그래프 레이아웃 조정
plt.tight_layout()
plt.show()
8) TimeSeriesSplit 이용한 시계열 교차 검증
##########################################################
# 파라미터 설정
##########################################################
seed_value = 42
set_seed(seed_value) # 위에서 정의한 함수 호출로 모든 시드 설정
num_output = 1
num_hidden = 10
num_features = len(features)
# hyper parameter
seq_length = 6 # 과거 6일의 데이터를 기반으로 다음날의 기온을 예측
batch_size = 32
learning_rate = 0.001
n_fold = 3
tscv = TimeSeriesSplit(n_splits=n_fold)
# 폴드별 성능 저장
fold_best_actuals_lst,fold_best_predictions_lst,fold_best_loss_lst,fold_best_epoch_lst = [],[],[],[]
for fold, (train_index, test_index) in enumerate(tscv.split(df_weather), start=1):
print(f"[Fold {fold}] 학습 및 검증 시작")
print(f"Test data index: {test_index[0]} ~ {test_index[-1]} ")
# 데이터 준비
sequence_dataX_train, sequence_dataY_train, \
sequence_dataX_test, sequence_dataY_test, \
(scaler_x, scaler_y) = prepare_scaled_sequences(df_weather, features, target_col, seq_length, train_index, test_index)
# DataLoader 생성
train_loader, test_loader = create_data_loaders_from_sequences(
sequence_dataX_train, sequence_dataY_train,
sequence_dataX_test, sequence_dataY_test,
batch_size = 32
)
# 모델 인스턴스 생성
model_lstm = LSTMModel(input_size=num_features, hidden_size=num_hidden, num_layers=1, output_size=num_output).to(device)
optimizer_lstm = torch.optim.Adam(model_lstm.parameters(), lr=learning_rate)
criterion_lstm = nn.MSELoss()
# 학습
train_loss_lst,test_loss_lst = [], []
best_actuals, best_predictions = [], [] # 초기화
best_loss = float('inf')
max_epochs = 150
for epoch in range(max_epochs):
train_loss = train(model_lstm, train_loader, optimizer_lstm, criterion_lstm)
test_loss, actuals, predictions = validate_model(model_lstm, test_loader, criterion_lstm)
train_loss_lst.append(train_loss)
test_loss_lst.append(test_loss)
if test_loss < best_loss:
best_loss = test_loss
best_epoch = epoch
best_actuals = actuals
best_predictions = predictions
if (epoch+1) % 10 == 0:
print(f"epoch {epoch+1}: train loss(mse) = {train_loss:.4f} test loss(mse) = {test_loss:.4f}")
print(f"Fold {fold} 학습 완료 : 총 {epoch+1} epoch")
actuals_original = scaler_y.inverse_transform(np.array(best_actuals).reshape(-1,1))
best_predictions_original = scaler_y.inverse_transform(np.array(best_predictions).reshape(-1,1))
fold_best_actuals_lst.append(actuals_original)
fold_best_predictions_lst.append(best_predictions_original)
fold_best_loss_lst.append(best_loss)
fold_best_epoch_lst.append(best_epoch)
plot_results(train_loss_lst, test_loss_lst, best_actuals, best_predictions, fold)
print("-----------------------------------------------------")
for fold in range(tscv.n_splits):
print(f"폴드 {fold} best 테스트 손실 (MSE) : {round(np.mean(fold_best_loss_lst[fold]),4)} at {best_epoch} epoch: ")
print(f"폴드 테스트 평균 손실 (MSE) : {round(np.mean(fold_best_loss_lst),4)}")[Fold 1] 학습 및 검증 시작
Test data index: 184 ~ 365
epoch 10: train loss(mse) = 0.6398 test loss(mse) = 1.0315
epoch 20: train loss(mse) = 0.2982 test loss(mse) = 0.5544
epoch 30: train loss(mse) = 0.1898 test loss(mse) = 0.3568
epoch 40: train loss(mse) = 0.1436 test loss(mse) = 0.2717
epoch 50: train loss(mse) = 0.1270 test loss(mse) = 0.2376
epoch 60: train loss(mse) = 0.1079 test loss(mse) = 0.2148
epoch 70: train loss(mse) = 0.1010 test loss(mse) = 0.2028
epoch 80: train loss(mse) = 0.0985 test loss(mse) = 0.1915
epoch 90: train loss(mse) = 0.0866 test loss(mse) = 0.1836
epoch 100: train loss(mse) = 0.0832 test loss(mse) = 0.1752
epoch 110: train loss(mse) = 0.0774 test loss(mse) = 0.1677
epoch 120: train loss(mse) = 0.0746 test loss(mse) = 0.1613
epoch 130: train loss(mse) = 0.0702 test loss(mse) = 0.1565
epoch 140: train loss(mse) = 0.0691 test loss(mse) = 0.1524
epoch 150: train loss(mse) = 0.0647 test loss(mse) = 0.1484
Fold 1 학습 완료 : 총 150 epoch

[Fold 2] 학습 및 검증 시작
Test data index: 366 ~ 547
epoch 10: train loss(mse) = 0.2510 test loss(mse) = 0.2312
epoch 20: train loss(mse) = 0.1175 test loss(mse) = 0.1031
epoch 30: train loss(mse) = 0.0898 test loss(mse) = 0.0849
epoch 40: train loss(mse) = 0.0811 test loss(mse) = 0.0761
epoch 50: train loss(mse) = 0.0741 test loss(mse) = 0.0717
epoch 60: train loss(mse) = 0.0643 test loss(mse) = 0.0678
epoch 70: train loss(mse) = 0.0661 test loss(mse) = 0.0635
epoch 80: train loss(mse) = 0.0578 test loss(mse) = 0.0622
epoch 90: train loss(mse) = 0.0603 test loss(mse) = 0.0595
epoch 100: train loss(mse) = 0.0551 test loss(mse) = 0.0576
epoch 110: train loss(mse) = 0.0503 test loss(mse) = 0.0577
epoch 120: train loss(mse) = 0.0517 test loss(mse) = 0.0565
epoch 130: train loss(mse) = 0.0485 test loss(mse) = 0.0547
epoch 140: train loss(mse) = 0.0484 test loss(mse) = 0.0548
epoch 150: train loss(mse) = 0.0453 test loss(mse) = 0.0550
Fold 2 학습 완료 : 총 150 epoch

[Fold 3] 학습 및 검증 시작
Test data index: 548 ~ 729
epoch 10: train loss(mse) = 0.1744 test loss(mse) = 0.2101
epoch 20: train loss(mse) = 0.0931 test loss(mse) = 0.1186
epoch 30: train loss(mse) = 0.0723 test loss(mse) = 0.0908
epoch 40: train loss(mse) = 0.0627 test loss(mse) = 0.0776
epoch 50: train loss(mse) = 0.0570 test loss(mse) = 0.0728
epoch 60: train loss(mse) = 0.0535 test loss(mse) = 0.0709
epoch 70: train loss(mse) = 0.0510 test loss(mse) = 0.0675
epoch 80: train loss(mse) = 0.0491 test loss(mse) = 0.0641
epoch 90: train loss(mse) = 0.0474 test loss(mse) = 0.0639
epoch 100: train loss(mse) = 0.0458 test loss(mse) = 0.0627
epoch 110: train loss(mse) = 0.0441 test loss(mse) = 0.0610
epoch 120: train loss(mse) = 0.0428 test loss(mse) = 0.0605
epoch 130: train loss(mse) = 0.0418 test loss(mse) = 0.0608
epoch 140: train loss(mse) = 0.0401 test loss(mse) = 0.0598
epoch 150: train loss(mse) = 0.0389 test loss(mse) = 0.0596
Fold 3 학습 완료 : 총 150 epoch
-----------------------------------------------------
폴드 0 best 테스트 손실 (MSE) : 0.1484 at 148 epoch:
폴드 1 best 테스트 손실 (MSE) : 0.0523 at 148 epoch:
폴드 2 best 테스트 손실 (MSE) : 0.0571 at 148 epoch:
폴드 테스트 평균 손실 (MSE) : 0.0859
※ 결과 해석
TimeSeriesSplit을 사용하여 시계열 데이터를 세 개의 폴드로 나누어 모델을 평가했습니다. 이 방법의 핵심은 시간의 흐름을 고려하여 데이터를 분할하는 것입니다. 결과를 분석해보면, Fold 1에서 Fold 3으로 갈수록 모델의 성능이 눈에 띄게 향상되는 것을 관찰할 수 있습니 다.
1) 학습 데이터 증가에 따른 성능 향상
Fold 1에서는 가장 적은 양의 데이터로 학습을 시작합니다. Fold 2에서는 Fold 1의 학습 데이터에 추가 데이터를 포함하여 학습하고, Fold 3에서는 더 많은 데이터를 사용합니다. 이러한 누적 효과로 인해 각 폴드에서 모델의 성능이 점진적으로 향상됩니다.
Fold 1의 최종 MSE: 0.1728 Fold 2의 최종 MSE: 0.0458 Fold 3의 최종 MSE: 0.0626
Fold 1에서 Fold 2로 넘어갈 때 성능이 크게 향상되었고, Fold 3에서도 Fold 1보다 훨씬 좋은 성능을 유지하고 있습니다.
2) 모델의 일반화 능력 향상
더 많은 데이터로 학습할수록 모델은 다양한 패턴과 변동성을 접하게 됩니다. 이는 모델이 새로운, 보지 못한 데이터에 대해서도 더 잘 예측할 수 있게 만듭니다. Fold 2와 Fold 3에서 train loss와 test loss의 차이가 Fold 1보다 작아진 것이 이를 뒷받침합니다.
3) 학습 곡선의 안정화
Fold 1의 학습 곡선을 보면 train loss와 test loss 사이의 간격이 크고, 변동성이 높습니다. 반면 Fold 2와 Fold 3에서는 두 loss 간의 간격이 좁아지고, 곡선이 더 부드러워집니다. 이는 모델이 더 안정적으로 학습되고 있음을 나타냅니다.
4) 과적합 위험 감소
더 많은 데이터로 학습하면 모델이 특정 패턴에 과도하게 맞추어지는 과적합의 위험이 줄어듭니다. Fold 2와 Fold 3에서 train loss와 test loss가 더 가깝게 유지되는 것이 이를 보여줍니다.
5) 장기 패턴 학습
시간이 지날수록 모델은 더 긴 기간의 데이터를 학습하게 됩니다. 이는 계절성이나 장기적인 트렌드와 같은 복잡한 패턴을 포착하는 데 도움이 됩니다. Fold 3에서의 안정적인 성능은 이러한 장기 패턴 학습의 결과로 볼 수 있습니다.
결론적으로, TimeSeriesSplit을 통한 이번 실험은 시계열 데이터 분석에서 데이터의 양이 모델의 성능과 안정성에 미치는 중요한 영향을 잘 보여줍니다. 시간이 지나고 더 많은 데이터가 누적될수록 모델의 예측 능력이 향상되며, 이는 실제 응용에서 매우 중요한 의미를 갖습니다. 따라서 실제 시계열 예측 모델을 개발할 때는 가능한 한 많은 과거 데이터를 활용하여 학습시키는 것이 좋으며, 지속적으로 새로운 데이터로 모델을 업데이트하는 것이 성능 유지와 향상에 도움이 될 것입니다.
4. Sliding Window 방식 교차 검증
Sliding Window 검증은 시계열 데이터를 평가하는 효과적인 방법 중 하나입니다. 이 방식은 고정된 크기의 "윈도우"를 시간축을 따라 이동시키면서 데이터를 분할합니다. 이는 각 시점에서 일정 기간의 과거 데이터를 사용하여 모델을 학습하고, 바로 다음 기간을 예측하는 실제 운영 환경을 시뮬레이션하는데 적합합니다.
TimeSeriesSplit과의 주요 차이점은 데이터 사용 방식에 있습니다. Sliding Window는 각 폴드에서 동일한 크기의 학습 데이터를 사용하여 일관된 평가를 가능하게 하는 반면, TimeSeriesSplit은 후반 폴드로 갈수록 학습 데이터의 양이 증가합니다. 또한, Sliding Window는 모든 데이터 포인트를 고르게 활용하지만, TimeSeriesSplit은 초기 데이터를 주로 학습에만 사용하는 경향이 있습니다.
Sliding Window 방식의 장점:
일관된 학습 데이터 크기를 사용하여 각 시점에서의 모델 성능을 공정하게 비교할 수 있습니다. 또한, 윈도우 가 시간에 따라 이동하면서 데이터의 지역적 변화를 잘 포착할 수 있어, 시간에 따른 패턴 변화를 분석하는 데 유용합니다. 그리고 각 폴드에서 최근 데이터의 중요성을 잘 반영할 수 있어, 시간에 따른 트렌드 변화를 잘 파악할 수 있습니다.
Sliding Window 방식의 단점:
TimeSeriesSplit에 비해 더 많은 폴드를 생성할 수 있어 계산 비용이 증가할 수 있습니다. 또한, 고정된 크기 의 윈도우를 사용하기 때문에 매우 장기적인 트렌드를 파악하기 어려울 수 있습니다. 마지막으로, 적절한 윈도우 크기를 선택하는 것이 중요한데, 이는 도메인 지식과 여러 실험을 통해 결정해야 하므로 추가적인 노력이 필요할 수 있습니다.
1) Sliding Window Split 함수 구현 및 실습
import numpy as np
def sliding_window_split(data, train_size, test_size, seq_length):
splits = []
start = len(data) - (train_size + test_size)
while start >= seq_length - 1:
train_index = np.arange(start, start + train_size)
test_index = np.arange(start + train_size, start + train_size + test_size)
splits.append((train_index, test_index))
start -= test_size # 테스트 데이터 크기만큼 이동
return splits[::-1] # 최신 폴드가 마지막에 오도록 순서 반전# 예제 데이터 생성
data = np.arange(30) # 0부터 29까지의 숫자 배열
print("전체 데이터:", data)
# Rolling Window (with fixed train set) 설정
train_size_ex = 15 # 학습 데이터 크기
test_size_ex = 5 # 테스트 데이터 크기
seq_length_ex = 3 # 시퀀스 길이
# 데이터 분할
splits_ex = sliding_window_split(data, train_size_ex, test_size_ex, seq_length_ex)
# 각 폴드 출력
for fold, (train_index, test_index) in enumerate(splits_ex, start=1):
print(f"Fold {fold}")
print(f"Train data: {data[train_index]}")
print(f"Test data: {data[test_index]}")
print("-" * 50)
fold += 1전체 데이터: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
24 25 26 27 28 29]
Fold 1
Train data: [ 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]
Test data: [20 21 22 23 24]
--------------------------------------------------
Fold 2
Train data: [10 11 12 13 14 15 16 17 18 19 20 21 22 23 24]
Test data: [25 26 27 28 29]
--------------------------------------------------
※ 결과 해석
이 예제에서는 Sliding Window 방식을 사용하여 30개의 데이터 포인트를 2개의 폴드로 나누었습니 다. 각 폴드는 15개의 학습 데이터와 5개의 테스트 데이터로 구성됩니다.
1)각 폴드의 학습 데이터 크기가 일정(15개)하게 유지됩니다. 이는 TimeSeriesSplit과 달리, 모든 폴 드에서 동일한 양의 데이터로 모델을 학습하고 평 가할 수 있게 해줍니다.
2) 윈도우가 5개 데이터 포인트씩 이동하면서 새로운 폴드를 생성합니다. 이를 통해 시간의 흐름에 따른 데이터의 변화를 단계적으로 반영할 수 있습니다.
3) 최신 데이터(25-29)가 마지막 폴드의 테스트 세트 로 사용됩니다. 이는 가장 최근의 데이터로 모델의 성능을 평가할 수 있게 해줍니다.
이러한 특성으로 인해 Sliding Window 방식은 시 간에 따른 모델 성능의 변화를 일관되게 평가하면서도, 데이터의 시간적 특성을 잘 반영할 수 있습니다.
2) 슬라이딩 윈도우 분할을 이용한 데이터 분할 실습
# 데이터 분할
splits_ex = sliding_window_split(df_weather.values, train_size=360, test_size=120, seq_length=6)
# 각 폴드 출력
for fold, (train_index, test_index) in enumerate(splits_ex, start=1):
print(f"Fold {fold}")
print(f"Train data index: {train_index[0]} ~ {train_index[-1]} ")
print(f"Test data index: {test_index[0]} ~ {test_index[-1]} ")
print("-" * 50)Fold 1
Train data index: 10 ~ 369
Test data index: 370 ~ 489
--------------------------------------------------
Fold 2
Train data index: 130 ~ 489
Test data index: 490 ~ 609
--------------------------------------------------
Fold 3
Train data index: 250 ~ 609
Test data index: 610 ~ 729
--------------------------------------------------
3) Sliding Window 방식의 교차 검증
##########################################################
# 파라미터 설정
##########################################################
seed_value = 42
set_seed(seed_value) # 위에서 정의한 함수 호출로 모든 시드 설정
num_output = 1
num_hidden = 10
num_features = len(features)
# hyper parameter
seq_length = 6 # 과거 6일의 데이터를 기반으로 다음날의 기온을 예측
batch_size = 32
learning_rate = 0.001
# Rolling Window 설정
train_size = 360
test_size = 120
splits = sliding_window_split(df_weather.values, train_size, test_size, seq_length)
# 폴드별 성능 저장
fold_best_actuals_lst,fold_best_predictions_lst,fold_best_loss_lst,fold_best_epoch_lst = [],[],[],[]
for fold, (train_index, test_index) in enumerate(splits, start=1):
print(f"[Fold {fold}] 학습 및 검증 시작")
print(f"Test data index: {test_index[0]} ~ {test_index[-1]}")
# 데이터 준비
sequence_dataX_train, sequence_dataY_train, sequence_dataX_test, sequence_dataY_test, (scaler_x, scaler_y) = prepare_scaled_sequences(df_weather, features, target_col, seq_length, train_index, test_index)
# DataLoader 생성
train_loader, test_loader = create_data_loaders_from_sequences(
sequence_dataX_train, sequence_dataY_train,
sequence_dataX_test, sequence_dataY_test,
batch_size = 32
)
# 모델 인스턴스 생성
model_lstm = LSTMModel(input_size=num_features, hidden_size=num_hidden, num_layers=1, output_size=num_output).to(device)
optimizer_lstm = torch.optim.Adam(model_lstm.parameters(), lr=learning_rate)
criterion_lstm = nn.MSELoss()
# 학습
train_loss_lst,test_loss_lst = [], []
best_actuals, best_predictions = [], [] # 초기화
best_loss = float('inf')
max_epochs = 150
for epoch in range(max_epochs):
train_loss = train(model_lstm, train_loader, optimizer_lstm, criterion_lstm)
test_loss, actuals, predictions = validate_model(model_lstm, test_loader, criterion_lstm)
train_loss_lst.append(train_loss)
test_loss_lst.append(test_loss)
if test_loss < best_loss:
best_loss = test_loss
best_epoch = epoch
best_actuals = actuals
best_predictions = predictions
if (epoch+1) % 10 == 0:
print(f"epoch {epoch+1}: train loss(mse) = {train_loss:.4f} test loss(mse) = {test_loss:.4f}")
print(f"Fold {fold} 학습 완료 : 총 {epoch+1} epoch")
actuals_original = scaler_y.inverse_transform(np.array(best_actuals).reshape(-1,1))
best_predictions_original = scaler_y.inverse_transform(np.array(best_predictions).reshape(-1,1))
fold_best_actuals_lst.append(actuals_original)
fold_best_predictions_lst.append(best_predictions_original)
fold_best_loss_lst.append(best_loss)
fold_best_epoch_lst.append(best_epoch)
plot_results(train_loss_lst, test_loss_lst, best_actuals, best_predictions, fold)
print("-----------------------------------------------------")
for fold in range(len(splits)):
print(f"폴드 {fold} best 테스트 손실 (MSE) : {round(np.mean(fold_best_loss_lst[fold]),4)} at {best_epoch} epoch: ")
print(f"폴드 테스트 평균 손실 (MSE) : {round(np.mean(fold_best_loss_lst),4)}")[Fold 1] 학습 및 검증 시작
Test data index: 370 ~ 489
epoch 10: train loss(mse) = 0.2819 test loss(mse) = 0.2053
epoch 20: train loss(mse) = 0.1571 test loss(mse) = 0.0988
epoch 30: train loss(mse) = 0.1065 test loss(mse) = 0.0738
epoch 40: train loss(mse) = 0.0737 test loss(mse) = 0.0627
epoch 50: train loss(mse) = 0.0813 test loss(mse) = 0.0594
epoch 60: train loss(mse) = 0.0653 test loss(mse) = 0.0535
epoch 70: train loss(mse) = 0.0591 test loss(mse) = 0.0518
epoch 80: train loss(mse) = 0.0569 test loss(mse) = 0.0548
epoch 90: train loss(mse) = 0.0545 test loss(mse) = 0.0509
epoch 100: train loss(mse) = 0.0593 test loss(mse) = 0.0530
epoch 110: train loss(mse) = 0.0581 test loss(mse) = 0.0506
epoch 120: train loss(mse) = 0.0512 test loss(mse) = 0.0507
epoch 130: train loss(mse) = 0.0495 test loss(mse) = 0.0515
epoch 140: train loss(mse) = 0.0570 test loss(mse) = 0.0505
epoch 150: train loss(mse) = 0.0824 test loss(mse) = 0.0538
Fold 1 학습 완료 : 총 150 epoch

[Fold 2] 학습 및 검증 시작
Test data index: 490 ~ 609
epoch 10: train loss(mse) = 0.1910 test loss(mse) = 0.1605
epoch 20: train loss(mse) = 0.0922 test loss(mse) = 0.0903
epoch 30: train loss(mse) = 0.0674 test loss(mse) = 0.0831
epoch 40: train loss(mse) = 0.0533 test loss(mse) = 0.0827
epoch 50: train loss(mse) = 0.0526 test loss(mse) = 0.0818
epoch 60: train loss(mse) = 0.0465 test loss(mse) = 0.0800
epoch 70: train loss(mse) = 0.0456 test loss(mse) = 0.0749
epoch 80: train loss(mse) = 0.0430 test loss(mse) = 0.0659
epoch 90: train loss(mse) = 0.0446 test loss(mse) = 0.0662
epoch 100: train loss(mse) = 0.0411 test loss(mse) = 0.0656
epoch 110: train loss(mse) = 0.0421 test loss(mse) = 0.0632
epoch 120: train loss(mse) = 0.0393 test loss(mse) = 0.0592
epoch 130: train loss(mse) = 0.0396 test loss(mse) = 0.0585
epoch 140: train loss(mse) = 0.0375 test loss(mse) = 0.0569
epoch 150: train loss(mse) = 0.0377 test loss(mse) = 0.0532
Fold 2 학습 완료 : 총 150 epoch

[Fold 3] 학습 및 검증 시작
Test data index: 610 ~ 729
epoch 10: train loss(mse) = 0.3460 test loss(mse) = 0.4564
epoch 20: train loss(mse) = 0.0972 test loss(mse) = 0.2039
epoch 30: train loss(mse) = 0.0878 test loss(mse) = 0.1676
epoch 40: train loss(mse) = 0.0743 test loss(mse) = 0.1309
epoch 50: train loss(mse) = 0.0598 test loss(mse) = 0.1128
epoch 60: train loss(mse) = 0.0845 test loss(mse) = 0.0967
epoch 70: train loss(mse) = 0.0508 test loss(mse) = 0.0861
epoch 80: train loss(mse) = 0.0448 test loss(mse) = 0.0824
epoch 90: train loss(mse) = 0.0431 test loss(mse) = 0.0733
epoch 100: train loss(mse) = 0.0409 test loss(mse) = 0.0708
epoch 110: train loss(mse) = 0.0405 test loss(mse) = 0.0728
epoch 120: train loss(mse) = 0.0386 test loss(mse) = 0.0725
epoch 130: train loss(mse) = 0.0417 test loss(mse) = 0.0729
epoch 140: train loss(mse) = 0.0427 test loss(mse) = 0.0684
epoch 150: train loss(mse) = 0.0361 test loss(mse) = 0.0649
Fold 3 학습 완료 : 총 150 epoch

-----------------------------------------------------
폴드 0 best 테스트 손실 (MSE) : 0.0496 at 149 epoch:
폴드 1 best 테스트 손실 (MSE) : 0.0484 at 149 epoch:
폴드 2 best 테스트 손실 (MSE) : 0.0649 at 149 epoch:
폴드 테스트 평균 손실 (MSE) : 0.0543
※ 결과 해석
1) 일관된 학습 패턴
모든 폴드에서 비슷한 학습 패턴을 보입니다. 초기에 손실이 급격히 감소하다가 점차 안정화되는 모습을 보입니다. 이는 모델이 각 폴드에 서 일관되게 학습하고 있음을 나타냅니다.
2) 과적합 관리
대부분의 경우 학습 손실(train loss)과 테스트 손실(test loss) 간의 격차가 크지 않습니다. 이는 모델이 과적합되지 않고 잘 일반화되고 있음을 시사합니다.
3) 폴드 간 성능 차이
Fold 1: 최종 MSE 0.0496 (115 에포크) Fold 2: 최종 MSE 0.0484 (146 에포크) Fold 3: 최종 MSE 0.0649 (149 에포크) Fold 1과 2는 비슷한 성능을 보이지만, Fold 3에서 성능이 다소 저하됩니다. 이는 시간이 지남에 따라 데이터의 패턴이 변화하고 있음을 암시할 수 있습 니다.
4) 시간에 따른 예측 난이도
Fold 3에서 성능이 다소 저하된 것은 최근 데이터에서 예측이 더 어려워졌음을 의미할 수 있습니다. 이는 날씨 패턴의 변화나 새로운 요인의 등장 등을 암시할 수 있습니다.
결론적으로, 이 Sliding Window 방식의 교차 검증은 시간에 따른 모델의 성능 변화를 잘 보여주고 있습니다. 전반적으로 모델은 안정적으로 학습되고 있지만, 최근 데이터에서 예측이 더 어려워지는 추세를 보입니 다. 이는 모델을 실제 운용할 때 주기적인 재학습이나 최신 데이터에 대한 적응이 필요할 수 있음을 시사합니다.