1. 데이터 로드
import pandas as pd
import numpy as np
train = pd.read_csv('train_prep.csv')
test = pd.read_csv('test_prep.csv')
# 'date'를 제외한 컬럼 저장하기
features_org = train.columns[1:]
# 'date' 컬럼을 datetime 타입으로 변경
train['date'] = pd.to_datetime(train['date'])
test['date'] = pd.to_datetime(test['date'])
train.head()
2. 전체 train 데이터에서 실제 학습 기간 및 품목 설정하기
분석기간 item_selected과 start_date_train를 원하는 품목과 기간으로 설정하여, 이후 분석을 수행합니다.
# 연-월 혹은 연-월-일 설정
start_date_train = '2020-01'
train_selected = train[train['date'] >= start_date_train].copy().reset_index(drop=True)
# '배추', '무', '깻잎', '시금치', '토마토', '청상추', 캠벨얼리', '샤인마스캇
item_selected = '배추'3. Feature engineering (1): 날짜 관련 feature 추가
- train_selected['date']에서 주(week) 정보를 ISO 주차로 추출합니다. dt.isocalendar().week를 사용하여 ISO 주차 정보를 가져올 수 있습니다. 이후에 astype(np.int32)를 사용하여 데이터 타입을 정수로 변환합니다.
# 날짜 관련 feature 추가 하기
train_selected['month'] = train_selected['date'].dt.month
train_selected['week'] = train_selected['date'].dt.isocalendar().week.astype(np.int32)
train_selected['weekday'] = train_selected['date'].dt.weekday
# 날자 관련 피처를 저장해 둔다.
features_date = ['month', 'week', 'weekday']
display(train_selected.columns)Index(['date', '배추_거래량', '배추_가격', '무_거래량', '무_가격', '깻잎_거래량', '깻잎_가격',
'시금치_거래량', '시금치_가격', '토마토_거래량', '토마토_가격', '청상추_거래량', '청상추_가격',
'캠벨얼리_거래량', '캠벨얼리_가격', '샤인마스캇_거래량', '샤인마스캇_가격', 'month', 'week',
'weekday'],
dtype='object')4. Feature Engineering (2) : 7일 차분 가격중 자기 상관성 높은 데이터 피처로 생성하기
1) 7일 차분(Difference)의 자기 상관성 (ACF), 부분 자기 상관성 (PACF) 그래프 그리기
시계열 데이터 분석에서 자주 사용되는 ACF와 PACF는 각각 다른 측면의 상관성을 보여주며, 피처 엔지니어링에서 중요한 역할을 할 수 있습니다.
※ ACF (AutoCorrelation Function)
전체적인 상관성: ACF는 여러 lag의 영향을 모두 포함하여 목표 변수와의 상관성을 측정합니다.
※ PACF (Partial AutoCorrelation Function)
순수한 상관성: PACF는 특정 lag만의 영향을 분리하여 목표 변수와의 상관성을 측정합니다.
다중공선성 감소 : 각 lag가 독립적으로 목표 변수에 미치는 영향을 보여줌으로써, 다중공선성 문제를 상대적으로 줄일 수 있습니다.
따라서, PACF를 사용하여 더 정확하고 유용한 피처를 생성하는 아이디어를 생각해 볼 수 있습니다.
import matplotlib.pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
# 7일 차분을 적용한 데이터를 생성
train_price_diff = train_selected[['date', f'{item_selected}_가격']].copy().diff(7).dropna()
train_price_diff.set_index('date', inplace = True)
fig, ax = plt.subplots(1,2 ,figsize = (12, 4))
# ACF (AutoCorrelation Function) 그래프 그리기
plot_acf(train_price_diff[f'{item_selected}_가격'], lags=50, title=f'ACF ({item_selected}_가격)_차분', ax=ax[0])
# PACF (Partial AutoCorrelation Function) 그래프 그리기
plot_pacf(train_price_diff[f'{item_selected}_가격'], lags=50, title=f'PACF ({item_selected}_가격_차분)', ax=ax[1])
plt.tight_layout()
plt.show()
※ 결과 해석

PACF 그래프를 보면, 약 7일, 14일, 21일 지연값에서 상대적으로 높은 값을 보입니다. 이 값들은 신뢰 구간을 넘어서는 것으로 보여, 데이터에 약 7일 주기의 패턴이 있을 수 있음을 시사합니다. 이러한 주기성은 가격 예측에 사용될 수 있는 중요한 피처가 될 가능성이 있습니다. 예를들어, 7일 이동 평균과 같은 피처를 새롭게 생성하여 모델의 성능을 향상시킬 수 있는 아이디어를 제공합니다.
2) 유의미한 시차(lag) 값 찾기를 위한 PACF(Partial AutoCorrelation Function) 계산
주어진 시계열 데이터 train_price_diff의 가격 변동(f'{item_selected}_가격')에 대해 PACF를 계산하여, 특정 신뢰 수준(95%)을 넘어서는 유의미한 시차(lag) 값을 찾습니다.
- 필요한 모듈과 함수를 임포트합니다. statsmodels.tsa.stattools에서 acf와 pacf를 임포트해야 합니다. 이 함수들은 자기상관 함수(AutoCorrelation Function)와 부분 자기상관 함수(Partial AutoCorrelation Function)의 값을 계산해줍니다.
- pacf 함수를 사용하여 부분 자기상관 함수(PACF) 값을 계산합니다. 입력으로 사용되는 데이터는 7일 차분이 적용된 배추 가격입니다. nlags=50으로 설정하여 50개의 래그(lag)에 대한 PACF 값을 계산하고, method='ols' 옵션을 사용하여 최소자승법(Ordinary Least Squares)으로 PACF 값을 계산합니다.
- 95% 신뢰수준에 해당하는 임계값을 계산합니다. 이는 1.96 / np.sqrt(len(train_price_diff)) 공식을 사용하여 계산할 수 있습니다.
- 계산된 PACF 값 중에서 신뢰수준을 넘어서는 값들의 인덱스를 찾습니다. 이를 위해 np.where 함수와 신뢰수준을 사용하여 계산합니다. np.where 함수는 조건에 맞는 인덱스를 반환합니다.
from statsmodels.tsa.stattools import acf, pacf
# PACF 계산
pacf_values = pacf(train_price_diff[f'{item_selected}_가격'], nlags=50, method='ols')
# 신뢰수준 계산 (95% 신뢰수준)
confidence_level = 1.96 / np.sqrt(len(train_price_diff))
# 신뢰수준을 넘어서는 PACF 값 찾기
significant_diff_lags_pacf = np.where(np.abs(pacf_values) >= confidence_level)[0]
display(significant_diff_lags_pacf)array([ 0, 1, 2, 7, 8, 9, 13, 14, 15, 20, 21, 22, 24, 28, 29, 35, 38,
42, 43, 47])
※ 결과 해석
실행 결과로 반환된 값들 [0, 1, 2, 7, 8, 9, 13, 14, 15, 20, 21, 22, 24, 28, 29, 35, 38, 42, 43, 47]은 현재 시점의 가격 변동과 연관성이 있는 과거의 시점들을 나타냅니다.
예를 들면, 값 7은 현재부터 7일 전의 데이터가 현재 가격 변동에 중요한 영향을 미칠 수 있다는 것을 의미합니다. 이러한 시차 값들은 미래 가격 변동을 예측하는 데 유용한 피처로 활용될 수 있습니다.
3) 보정된 Lag 값을 이용하여 피처 목록 생성
# 1주, 2주, 4주 후 가격 변동량 예측을 위해 각각 7, 14, 28을 빼서 보정
# 이는 현 시점과 과거 시점의 가격 변동량의 연관성을 보정하여 미래 예측에 적용하기 위함
significant_diff_lags_1week_predict = significant_diff_lags_pacf - 7
significant_diff_lags_2week_predict = significant_diff_lags_pacf - 14
significant_diff_lags_4week_predict = significant_diff_lags_pacf - 28
# 보정된 lag 값이 0 이상인 것만 선택. 음수 값은 무시.
significant_diff_lags_1week_predict = significant_diff_lags_1week_predict[ significant_diff_lags_1week_predict >= 0]
significant_diff_lags_2week_predict = significant_diff_lags_2week_predict[ significant_diff_lags_2week_predict >= 0]
significant_diff_lags_4week_predict = significant_diff_lags_4week_predict[ significant_diff_lags_4week_predict >= 0]
# 향후 feature 추출을 위해 lag관련 feature list를 저장해 둔다
features_diff_lags_1week ,features_diff_lags_2week,features_diff_lags_4week = [], [], []
for n_lag in significant_diff_lags_1week_predict:
if n_lag == 0:
features_diff_lags_1week.append(f'{item_selected}_가격_diff7')
else:
features_diff_lags_1week.append(f'{item_selected}_가격_diff7_lag{n_lag}')
for n_lag in significant_diff_lags_2week_predict:
if n_lag == 0:
features_diff_lags_2week.append(f'{item_selected}_가격_diff7')
else:
features_diff_lags_2week.append(f'{item_selected}_가격_diff7_lag{n_lag}')
for n_lag in significant_diff_lags_4week_predict:
if n_lag == 0:
features_diff_lags_4week.append(f'{item_selected}_가격_diff7')
else:
features_diff_lags_4week.append(f'{item_selected}_가격_diff7_lag{n_lag}')
display(f'features_diff_lags_1week : {features_diff_lags_1week}')
display(f'features_diff_lags_2week : {features_diff_lags_2week}')
display(f'features_diff_lags_4week : {features_diff_lags_4week}')"features_diff_lags_1week : ['배추_가격_diff7', '배추_가격_diff7_lag1', '배추_가격_diff7_lag2', '배추_가격_diff7_lag6', '배추_가격_diff7_lag7', '배추_가격_diff7_lag8', '배추_가격_diff7_lag13', '배추_가격_diff7_lag14', '배추_가격_diff7_lag15', '배추_가격_diff7_lag17', '배추_가격_diff7_lag21', '배추_가격_diff7_lag22', '배추_가격_diff7_lag28', '배추_가격_diff7_lag31', '배추_가격_diff7_lag35', '배추_가격_diff7_lag36', '배추_가격_diff7_lag40']""features_diff_lags_2week : ['배추_가격_diff7', '배추_가격_diff7_lag1', '배추_가격_diff7_lag6', '배추_가격_diff7_lag7', '배추_가격_diff7_lag8', '배추_가격_diff7_lag10', '배추_가격_diff7_lag14', '배추_가격_diff7_lag15', '배추_가격_diff7_lag21', '배추_가격_diff7_lag24', '배추_가격_diff7_lag28', '배추_가격_diff7_lag29', '배추_가격_diff7_lag33']""features_diff_lags_4week : ['배추_가격_diff7', '배추_가격_diff7_lag1', '배추_가격_diff7_lag7', '배추_가격_diff7_lag10', '배추_가격_diff7_lag14', '배추_가격_diff7_lag15', '배추_가격_diff7_lag19']"
※ 코드 해석
significant_diff_lags_1week_predict = significant_diff_lags_pacf - 7
significant_diff_lags_2week_predict = significant_diff_lags_pacf - 14
significant_diff_lags_4week_predict = significant_diff_lags_pacf - 28
PACF 분석을 통해 얻은 lag 값은 현재 시점에서의 과거 데이터의 영향을 의미합니다. 그러나, 1주 후(7일 후)를 예측하려면 단순히 PACF 분석에서 나온 값이 아니라 7일 이전의 값을 기준으로 보정해야 합니다. 따라서 7일, 14일, 28일을 빼서 1주, 2주, 4주 후의 예측에 적합한 형태로 변환합니다.
significant_diff_lags_1week_predict = significant_diff_lags_1week_predict[ significant_diff_lags_1week_predict >= 0]
significant_diff_lags_2week_predict = significant_diff_lags_2week_predict[ significant_diff_lags_2week_predict >= 0]
significant_diff_lags_4week_predict = significant_diff_lags_4week_predict[ significant_diff_lags_4week_predict >= 0]
만약 significant_diff_lags_pacf에서 나온 lag 값이 7보다 작은 경우, significant_diff_lags_1week_predict = significant_diff_lags_pacf - 7을 적용하면 음수 값이 발생할 수 있습니다. 예를 들어 significant_diff_lags_pacf = [0, 1, 2, 7, 8, 9]라면: significant_diff_lags_1week_predict = [-7, -6, -5, 0, 1, 2] 이 중 -7, -6, -5 같은 음수 lag 값은 의미가 없으므로 제거합니다.
4) 실제 피처 생성과 데이터셋 업데이트
보정된 Lag 값을 이용하여 실제 데이터셋에 피처 추가합니다.
significant_diff_lags_all = set(list(significant_diff_lags_1week_predict)) | set(list(significant_diff_lags_2week_predict)) | set(list(significant_diff_lags_4week_predict))
# train_selected 컬럼 생성 하기
for diff_lag in list(significant_diff_lags_all):
if diff_lag == 0:
train_selected[f'{item_selected}_가격_diff7'] = train_selected[f'{item_selected}_가격'].copy().diff(7)
else:
train_selected[f'{item_selected}_가격_diff7_lag{diff_lag}'] = train_selected[f'{item_selected}_가격'].copy().diff(7).shift(diff_lag)
display(train_selected.columns)
display(train_selected.head(5))

※ 코드 해석
significant_diff_lags_all = set(list(significant_diff_lags_1week_predict)) | set(list(significant_diff_lags_2week_predict)) | set(list(significant_diff_lags_4week_predict))
1주, 2주,4주 예측을 위해 도출된 지연값들을 하나의 집합으로 합칩니다. 이렇게 하면 중복되는 지연값을 제거하고, 각 예측 시점에 대한 중요한 지연값만을 고려할 수 있습니다.
for diff_lag in list(significant_diff_lags_all):
if diff_lag == 0:
train_selected[f'{item_selected}_가격_diff7'] = train_selected[f'{item_selected}_가격'].copy().diff(7)
else:
train_selected[f'{item_selected}_가격_diff7_lag{diff_lag}'] = train_selected[f'{item_selected}_가격'].copy().diff(7).shift(diff_lag)
유의미한 지연값을 활용해 새로운 피처를 생성합니다. diff(7) 은 7일 간의 가격 변동을 나타냅니다. shift(diff_lag)는 diff_lag만큼 시점을 미룹니다. 예를 들어, diff_lag가 1일 경우 어제의 데이터를 사용하게 됩니다.
5. feature engineering (3) : 상관 관계 높은 타 품목의 과거 시점 1주일 가격 변동량
1) 타품목 과거 시점의 1,2,4주 동안의 가격 변동량과 예측대상의 최근 1,2,4주 동안의 가격 변동량과의 상관 관계
import seaborn as sns
correlation_matrix_diff_lst = []
for n_lag in [7,14,28]:
train_diff = pd.DataFrame()
for col in features_org:
if f'{item_selected}_가격' in col:
# 선택한 품목의 경우 n_lag 동안의 가격 변화율 계산
train_diff[f"{col}_diff{n_lag}"] = train_selected[col].diff(n_lag)
else:
# 타 품목의 경우 n_lag전의 n_lag 동안의 가격 변화율 계산
train_diff[f"{col}_diff7_lag{n_lag}"] = train_selected[col].diff(n_lag).shift(n_lag)
train_diff = train_diff.dropna()
# 상관 관계 행렬 계산
correlation_matrix_diff_lst.append(train_diff.corr())
# 3개의 서브플롯을 3x1 그리드로 생성
fig, axes = plt.subplots(3, 1, figsize=(12, 18))
# 각 시간 간격(7일, 14일, 28일)에 대한 상관 관계 행렬을 히트맵으로 그림
for i, (n_lag, ax) in enumerate(zip([7, 14, 28], axes)):
sns.heatmap(correlation_matrix_diff_lst[i], annot=True, fmt=".2f", cmap='coolwarm', ax=ax)
ax.set_title(f'향후 {n_lag}주일 가격 변동과 직전 {n_lag}주일 가격 변동간의 관계 matrix for {n_lag}-day Lag')
ax.set_xticklabels(ax.get_xticklabels(), rotation=45)
plt.tight_layout()
plt.show()

2) 상관 관계를 기반으로 한 타 품목의 가격 및 거래량 피처 생성
선택한 품목(item_selected)과 다른 품목들 간의 가격 및 거래량의 상관 관계를 분석합니다. 이를 통해 미래 가격 예측에 유용할 것으로 판단되는 타 품목의 가격과 거래량을 새로운 피처로 저장합니다.
features_other_item_1week, features_other_item_2week,features_other_item_4week = [],[],[]
# 유의미한 최소 상관 관계 값을 설정
critical_value = 0.2
for i, n_lag in enumerate([7,14,28]):
correlation_matrix_diff = correlation_matrix_diff_lst[i]
significant_corr_items = correlation_matrix_diff.loc[f'{item_selected}_가격_diff{n_lag}']
significant_corr_items = significant_corr_items[significant_corr_items.abs() > critical_value]
# 절대값 기준으로 정렬
significant_corr_items = significant_corr_items.iloc[significant_corr_items.abs().argsort()[::-1]]
# 자기 자신 제외
significant_corr_items = significant_corr_items.drop(f'{item_selected}_가격_diff{n_lag}')
# 품목 이름과 값 추출
significant_item_names = significant_corr_items.index.tolist()
significant_item_values = significant_corr_items.values.tolist()
# 1,2,4주 후를 예측하는 타품목 가격, 변동량을 피처로 저장해 둡니다.
if n_lag== 7:
features_other_item_1week = significant_item_names
corr_value_other_item_1week = significant_item_values
elif n_lag== 14:
features_other_item_2week = significant_item_names
corr_value_other_item_2week = significant_item_values
elif n_lag== 28:
features_other_item_4week = significant_item_names
corr_value_other_item_4week = significant_item_values
display(f'1week : {features_other_item_1week} : {corr_value_other_item_1week}')
display(f'2week : {features_other_item_2week} : {corr_value_other_item_2week}')
display(f'4week : {features_other_item_4week} : {corr_value_other_item_4week}')"1week : ['샤인마스캇_거래량_diff7_lag7', '캠벨얼리_거래량_diff7_lag7', '깻잎_가격_diff7_lag7', '시금치_가격_diff7_lag7'] : [0.2238288386596936, 0.21910945552239222, 0.21026419132791363, 0.20581444905949828]""2week : ['캠벨얼리_거래량_diff7_lag14', '시금치_가격_diff7_lag14'] : [0.40148612191932087, 0.2892311397093388]""4week : ['청상추_가격_diff7_lag28', '캠벨얼리_거래량_diff7_lag28', '샤인마스캇_거래량_diff7_lag28', '시금치_가격_diff7_lag28', '샤인마스캇_가격_diff7_lag28', '토마토_가격_diff7_lag28'] : [0.3380319023337659, 0.3028986771504423, -0.2756028194985533, 0.2491212656857217, -0.21572040892560307, -0.20312906206983133]"
3) 유의미한 상관 관계를 가진 타품목 가격, 거래량 변동량 피처 컬럼 생성
선택 픔목과 상관 관계가 있는 다른 품목들의 가격과 거래량 정보를 특성으로 추가합니다. 이를 위해 1주(7일), 2주(14일), 4주(28일)의 차이를 갖는 새로운 특성들을 생성합니다.
for features_other_item in [features_other_item_1week, features_other_item_2week, features_other_item_4week]:
# features_other_item 리스트를 순회하며 각 feature에 대한 처리를 수행
for feature in features_other_item:
# feature 문자열을 '_' 기준으로 분리
feature_split = feature.split('_')
# 분리된 문자열 중 첫 번째와 두 번째 부분을 '_'로 연결해 새로운 feature 이름을 생성
# 예: '배추_가격_1week_7' -> '배추_가격'
feature_name = feature_split[0] + '_' + feature_split[1]
# feature 문자열의 마지막 부분에서 lag 값을 추출
# 예: '배추_가격_1week_7' -> '7'
n_lag = int(feature_split[3][-1])
# diff 함수를 사용하여 n_lag만큼 차분을 한 후, 이를 새로운 컬럼에 저장
train_selected[feature] = train_selected[feature_name].diff(n_lag)
print(train_selected.columns)Index(['date', '배추_거래량', '배추_가격', '무_거래량', '무_가격', '깻잎_거래량', '깻잎_가격',
'시금치_거래량', '시금치_가격', '토마토_거래량', '토마토_가격', '청상추_거래량', '청상추_가격',
'캠벨얼리_거래량', '캠벨얼리_가격', '샤인마스캇_거래량', '샤인마스캇_가격', 'month', 'week',
'weekday', '배추_가격_diff7', '배추_가격_diff7_lag1', '배추_가격_diff7_lag2',
'배추_가격_diff7_lag6', '배추_가격_diff7_lag7', '배추_가격_diff7_lag8',
'배추_가격_diff7_lag10', '배추_가격_diff7_lag13', '배추_가격_diff7_lag14',
'배추_가격_diff7_lag15', '배추_가격_diff7_lag17', '배추_가격_diff7_lag19',
'배추_가격_diff7_lag21', '배추_가격_diff7_lag22', '배추_가격_diff7_lag24',
'배추_가격_diff7_lag28', '배추_가격_diff7_lag29', '배추_가격_diff7_lag31',
'배추_가격_diff7_lag33', '배추_가격_diff7_lag35', '배추_가격_diff7_lag36',
'배추_가격_diff7_lag40', '샤인마스캇_거래량_diff7_lag7', '캠벨얼리_거래량_diff7_lag7',
'깻잎_가격_diff7_lag7', '시금치_가격_diff7_lag7', '캠벨얼리_거래량_diff7_lag14',
'시금치_가격_diff7_lag14', '청상추_가격_diff7_lag28', '캠벨얼리_거래량_diff7_lag28',
'샤인마스캇_거래량_diff7_lag28', '시금치_가격_diff7_lag28', '샤인마스캇_가격_diff7_lag28',
'토마토_가격_diff7_lag28'],
dtype='object')6. feature engineering 3 : Exponential Moving Average (EMA)를 이용한 feature 생성
선택한 품목인 '배추'의 가격에 대해 7일, 14일, 28일의 창 크기(window size)로 지수 이동 평균(EMA)을 계산하고, 이 EMA 값과 실제 가격과의 퍼센트 변동율을 계산하고 이 값들로 피처를 생성합니다.
window_size = 7,14,28
# EMA 계산
features_ema = []
for window_size in [7,14,28]:
ema_column = f'{item_selected}_가격_EMA_{window_size}'
train_selected[ema_column] = train_selected[f'{item_selected}_가격'].ewm(span=window_size, adjust=False).mean()
# 퍼센트 변동율 계산
ema_pct_column = f'{item_selected}_가격_EMA_{window_size}_pct'
train_selected[ema_pct_column] = ((train_selected[ema_column] - train_selected[f'{item_selected}_가격']) / train_selected[f'{item_selected}_가격']) * 100
features_ema.append(ema_pct_column)
display(train_selected.columns)
# 지금까지 생성한 feature들로 발생한 NAN수 제거
train_selected = train_selected.dropna().reset_index(drop=True)
display(train_selected['date'].min(), train_selected['date'].max() )Index(['date', '배추_거래량', '배추_가격', '무_거래량', '무_가격', '깻잎_거래량', '깻잎_가격',
'시금치_거래량', '시금치_가격', '토마토_거래량', '토마토_가격', '청상추_거래량', '청상추_가격',
'캠벨얼리_거래량', '캠벨얼리_가격', '샤인마스캇_거래량', '샤인마스캇_가격', 'month', 'week',
'weekday', '배추_가격_diff7', '배추_가격_diff7_lag1', '배추_가격_diff7_lag2',
'배추_가격_diff7_lag6', '배추_가격_diff7_lag7', '배추_가격_diff7_lag8',
'배추_가격_diff7_lag10', '배추_가격_diff7_lag13', '배추_가격_diff7_lag14',
'배추_가격_diff7_lag15', '배추_가격_diff7_lag17', '배추_가격_diff7_lag19',
'배추_가격_diff7_lag21', '배추_가격_diff7_lag22', '배추_가격_diff7_lag24',
'배추_가격_diff7_lag28', '배추_가격_diff7_lag29', '배추_가격_diff7_lag31',
'배추_가격_diff7_lag33', '배추_가격_diff7_lag35', '배추_가격_diff7_lag36',
'배추_가격_diff7_lag40', '샤인마스캇_거래량_diff7_lag7', '캠벨얼리_거래량_diff7_lag7',
'깻잎_가격_diff7_lag7', '시금치_가격_diff7_lag7', '캠벨얼리_거래량_diff7_lag14',
'시금치_가격_diff7_lag14', '청상추_가격_diff7_lag28', '캠벨얼리_거래량_diff7_lag28',
'샤인마스캇_거래량_diff7_lag28', '시금치_가격_diff7_lag28', '샤인마스캇_가격_diff7_lag28',
'토마토_가격_diff7_lag28', '배추_가격_EMA_7', '배추_가격_EMA_7_pct', '배추_가격_EMA_14',
'배추_가격_EMA_14_pct', '배추_가격_EMA_28', '배추_가격_EMA_28_pct'],
dtype='object')Timestamp('2020-02-17 00:00:00')Timestamp('2021-09-27 00:00:00')
※ 결과 해석
7일, 14일, 28일의 창 크기를 갖는 EMA를 계산합니다. EMA는 평균을 취할 때 최근 데이터에 더 높은 가중치를 주는 방법입니다. 계산된 EMA와 실제 ‘배추’의 가격과의 퍼센트 변동률을 계산합니다. 이것은 실제 가격이 얼마나 EMA에서 벗어나 있는지를 백분율로 표현한 것입니다. 이 퍼센트 변동률을 새로운 특성으로 train_selected 데이터프레임에 추가합니다.
새로운 특성들이 train_selected 데이터프레임에 추가되었습니다.
(‘품목’_가격_EMA_7_pct’, ‘품목’_가격_EMA_14_pct’, ‘품목’_가격_EMA_28_pct’) 이러한 특성들은 (품목)의 가격이 일정 기간 동안 EMA에 비해 얼마나 변동하는지를 나타냅니다. 이 정보는 시계열 데이터에서 중요한 패턴을 학습하는 데 도움이 될 것입니다.
NaN 값 제거로 인해, train_selected는 2020년 2월 1일부터 2021년 9월 27일까지 날짜를 포함하고 있습니다. NaN값 제거 이전에는 2020년 1월 1일부터 포함되어 있었으나, EMA를 이용한 feature 생성으로 인해 이렇게 NaN수가 발생함을 인지하도록 합시다.
7. 1,2,4주 후 가격 예측을 위한 학습 데이터와 정답지 생성: 상대적 가격 변동을 반영한 타깃 값 설정
1주, 2주, 4주후의 가격을 예측하기 위한 정답지 변수, 예측 대상 날짜 컬럼을 함수로 만들어 생성하고, 1주,2주,4주후 예측을 위해 필요한 feature 리스트와 데이터를 각각 만듭니다.
# 'true_1week', 'true_2week', 'true_4week' 컬럼을 생성하기 위한 함수
def generate_target_columns(df, date_col, item , week):
item_price_name = f'{item}_가격'
target_price_name = f'true_{week}week'
target_price_diff_name = f'true_diff_{week}week'
target_date_name = f'date_{week}week'
for i, row in df.iterrows():
target_date = row[date_col] + pd.DateOffset(weeks=week)
target_value = df.loc[df[date_col] == target_date, item_price_name]
if not target_value.empty:
df.at[i, target_date_name] = target_date.date()
df.at[i, target_price_name] = target_value.values[0]
df.at[i, target_price_diff_name] = target_value.values[0] - row[item_price_name]
else:
df.at[i, target_date_name] = np.nan
df.at[i,target_price_name] = np.nan
df.at[i, target_price_diff_name] = np.nan
df = df.dropna().reset_index(drop=True)
return df
features_date = [f'{item_selected}_가격', 'month', 'week']
# 1,2,4주 후를 예측하는 모델에 필요한 피처 리스트를 각각 얻습니다.
features_1week = features_date + features_diff_lags_1week + features_other_item_1week + features_ema
features_2week = features_date + features_diff_lags_2week + features_other_item_2week + features_ema
features_4week = features_date + features_diff_lags_4week + features_other_item_4week + features_ema
# 1,2,4주 후를 예측하는 모델에 필요한 학습, 검증을 위한 데이터를 각각 생성합니다.
train_1week = train_selected[['date'] + features_1week].copy()
train_2week = train_selected[['date'] + features_2week].copy()
train_4week = train_selected[['date'] + features_4week].copy()
#1,2,4주 후를 예측하는 모델에 필요한 학습, 검증을 위한 데이터에 정답지 컬럼을 생성합니다.
train_1week = generate_target_columns(train_1week, 'date', item_selected, 1)
train_2week = generate_target_columns(train_2week, 'date', item_selected, 2)
train_4week = generate_target_columns(train_4week, 'date', item_selected, 4)
# 어떤 컬럼이 생성 되었는지 각각 확인
display(train_1week.columns)
display(train_2week.columns)
display(train_4week.columns)
# 생성된 컬럼 확인
display(train_1week[['date', f'{item_selected}_가격', f'date_1week', f'true_1week', f'true_diff_1week']].head(10))
8. LightGBM 모델을 활용한 1, 2, 4주 후 가격 변동량 예측과 모델 검증
from tqdm import tqdm
import lightgbm as lgb
import numpy as np
import pandas as pd
# NMAE (Normalized Mean Absolute Error)를 계산하는 함수 정의
def nmae(true_values, pred_values):
mask = true_values != 0
filtered_true_values = true_values[mask]
filtered_pred_values = pred_values[mask]
return np.sum(np.abs(filtered_true_values - filtered_pred_values) / filtered_true_values) / len(filtered_true_values)
def evaluate_lgbm_model(item_name, df, features, start_date, n_week, nmae_function, train_update_mode='no_update', model_params=None):
# 예측할 주차에 따른 타겟 컬럼 이름 설정
target_diff_price_col = f'true_diff_{n_week}week'
target_price_col = f'true_{n_week}week'
# 검증 데이터의 마지막 날짜 계산
end_date_valid = df['date'].max() - pd.Timedelta(weeks=n_week)
# 학습 및 검증 데이터 분리
_train_data = df[df['date'] < start_date].reset_index(drop=True)
_valid_data = df[df['date'] >= start_date].dropna().reset_index(drop=True)
# 검증할 날짜 목록 생성
valid_day_lst = _valid_data['date'].to_list()
# LightGBM 모델 파라미터 설정 및 학습
if model_params is None:
model_params = {'learning_rate': 0.01, 'num_leaves': 5, 'max_depth': 5, 'objective': 'regression', 'random_state': 42}
model_week = lgb.LGBMRegressor(**model_params, silent=True, verbosity=-1)
model_week.fit(_train_data[features], _train_data[target_diff_price_col])
# 실제값과 예측값을 저장할 리스트 초기화
true_week_lst, pred_week_lst = [], []
for idx, date in tqdm(enumerate(valid_day_lst), total=len(valid_day_lst)):
# 해당 날짜 이하의 검증 데이터
_valid_updated = _valid_data[_valid_data['date'] <= date]
# 해당 날짜의 마지막 상품 가격
_last_item_price = _valid_updated[f'{item_name}_가격'].values[-1]
if train_update_mode == 'no_update':
update_condition = False
elif train_update_mode == 'daily':
update_condition = True
elif train_update_mode == 'sunday':
update_condition = (idx == 0) or (date.weekday() == 6)
if update_condition:
_train_updated = pd.concat([_train_data, _valid_data[_valid_data['date'] < date]])
model_week = lgb.LGBMRegressor(**model_params, silent=True, verbosity=-1)
model_week.fit(_train_updated[features], _train_updated[target_diff_price_col])
# 모델을 통한 가격 변동량 예측
y_pred_diff_week = model_week.predict(_valid_updated[features].iloc[-1:])
# 예측된 가격 변화를 마지막 상품 가격에 더하여 예측 가격 얻음
y_pred_week = _last_item_price + y_pred_diff_week
# 실제 가격과 예측 가격을 리스트에 추가
true_week_lst.append(df.loc[df['date'] == date, target_price_col].values[0])
pred_week_lst.append(y_pred_week[0])
score = nmae_function(np.array(true_week_lst), np.array(pred_week_lst))
return score, pred_week_lst, model_week
start_date_valid = '2021-05-01'
# train_update_mode='weekly', 'no_update', 'daily', 'sunday'
score_1week, pred_1week, model_1week = evaluate_lgbm_model(item_selected, train_1week, features_1week, start_date_valid, n_week=1, nmae_function=nmae, train_update_mode='daily')
score_2week, pred_2week, model_2week = evaluate_lgbm_model(item_selected, train_2week, features_2week, start_date_valid, n_week=2, nmae_function=nmae, train_update_mode='daily')
score_4week, pred_4week, model_4week = evaluate_lgbm_model(item_selected, train_4week, features_4week, start_date_valid, n_week=4, nmae_function=nmae, train_update_mode='daily')
score_mean = (score_1week + score_2week + score_4week) / 3
display(f'mean nmae score : {score_mean} ({score_1week},{score_2week},{score_4week})')100%|██████████| 143/143 [00:02<00:00, 64.56it/s]
100%|██████████| 136/136 [00:01<00:00, 71.43it/s]
100%|██████████| 122/122 [00:01<00:00, 74.45it/s]
'mean nmae score : 0.20470338868658514 (0.17861038055875708,0.22444266574703792,0.2110571197539604)'9. Feature Selection
1) SelectFromModel에 의한 Feature Selection
※ SelectFromModel: 개념 및 작동 원리
- 개념: SelectFromModel은 scikit-learn 라이브러리에서 제공하는 특성 선택 메서드 중 하나입니다. 이 방법은 머신러닝 모델을 사용하여 특성의 중요도를 판별하고, 중요도가 특정 임계값 이상인 특성만 선택합니다.
- 작동 원리 모델 학습: 먼저, 데이터셋에 기반한 머신러닝 모델(예: 랜덤 포레스트, LGBM, SVM 등)을 학습시킵니다. 이 모델은 각 특성의 중요도를 평가할 수 있어야 합니다.
- 특성 중요도 산출: 학습된 모델을 기반으로 각 특성의 중요도를 산출합니다. 이 중요도는 모델의 feature_importances_ 속성, coef_ 속성 등을 통해 얻을 수 있습니다.
- 임계값 설정: 특성을 선택할 때 사용할 중요도 기준을 설정합니다. 임계값은 사용자가 직접 설정할 수도 있고, 학습된 모델의 중요도 분포를 기반으로 자동으로 설정할 수도 있습니다.
- 특성 선택: 설정된 임계값과 각 특성의 중요도를 비교하여, 중요도가 임계값 이상인 특성만 선택합니다.
scikit-learn 라이브러리에서 제공하는 특성 선택 메서드 중 하나인 SelectFromModel을 이용하여 지금까지 생성하였던 피처중에서 중요도를 판별하고, 중요도가 특정 임계값 이상인 특성만 선택합니다.
from sklearn.feature_selection import SelectFromModel
threshold_1week = 0.1
threshold_2week = 0.1
threshold_4week = 0.1
sfm_1week = SelectFromModel(model_1week, threshold=threshold_1week)
sfm_1week.fit(train_1week[features_1week], train_1week['true_diff_1week'])
sfm_features_1week = [feature for feature, is_important in zip(features_1week, sfm_1week.get_support()) if is_important]
sfm_2week = SelectFromModel(model_2week, threshold=threshold_2week)
sfm_2week.fit(train_2week[features_2week], train_2week['true_diff_2week'])
sfm_features_2week = [feature for feature, is_important in zip(features_2week, sfm_2week.get_support()) if is_important]
sfm_4week = SelectFromModel(model_4week, threshold=threshold_4week)
sfm_4week.fit(train_4week[features_4week], train_4week['true_diff_4week'])
sfm_features_4week = [feature for feature, is_important in zip(features_4week, sfm_4week.get_support()) if is_important]
display("sfm_features_1week (총 {len(sfm_features_1week)개}): " + ", ".join(sfm_features_1week))
display("sfm_features_2week (총 {len(sfm_features_2week)개}: " +", ".join(sfm_features_2week))
display("sfm_features_4week (총 {len(sfm_features_4week)개}: " +", ".join(sfm_features_4week))'sfm_features_1week (총 {len(sfm_features_1week)개}): 배추_가격, week, 배추_가격_diff7_lag1, 배추_가격_diff7_lag2, 배추_가격_diff7_lag6, 배추_가격_diff7_lag7, 배추_가격_diff7_lag14, 배추_가격_diff7_lag17, 배추_가격_diff7_lag28, 배추_가격_diff7_lag31, 배추_가격_diff7_lag40, 캠벨얼리_거래량_diff7_lag7, 깻잎_가격_diff7_lag7, 시금치_가격_diff7_lag7, 배추_가격_EMA_7_pct, 배추_가격_EMA_14_pct, 배추_가격_EMA_28_pct''sfm_features_2week (총 {len(sfm_features_2week)개}: 배추_가격, month, week, 배추_가격_diff7, 배추_가격_diff7_lag6, 배추_가격_diff7_lag10, 배추_가격_diff7_lag33, 캠벨얼리_거래량_diff7_lag14, 시금치_가격_diff7_lag14, 배추_가격_EMA_14_pct, 배추_가격_EMA_28_pct''sfm_features_4week (총 {len(sfm_features_4week)개}: 배추_가격, month, week, 배추_가격_diff7, 배추_가격_diff7_lag7, 시금치_가격_diff7_lag28, 샤인마스캇_가격_diff7_lag28, 토마토_가격_diff7_lag28, 배추_가격_EMA_14_pct'2) SelectFromModel 모델 통해 제거된 피처 확인
deleted_features_1week = set(features_1week) - set(sfm_features_1week)
deleted_features_2week = set(features_2week) - set(sfm_features_2week)
deleted_features_4week = set(features_4week) - set(sfm_features_4week)
display(f'features_1week (총 {len(features_1week)}개)에서 제거된 피처 : 총 {len(deleted_features_1week)}개')
display(f'제거된 features : {deleted_features_1week} \n')
display(f'features_2week (총 {len(features_2week)}개)에서 제거된 피처 : 총 {len(deleted_features_2week)}개')
display(f'제거된 features : {deleted_features_2week}')
display(f'features_4week (총 {len(features_4week)}개)에서 제거된 피처 : 총 {len(deleted_features_4week)}개')
display(f'제거된 features : {deleted_features_4week}')'features_1week (총 27개)에서 제거된 피처 : 총 10개'"제거된 features : {'month', '배추_가격_diff7_lag36', '샤인마스캇_거래량_diff7_lag7', '배추_가격_diff7_lag13', '배추_가격_diff7_lag22', '배추_가격_diff7_lag21', '배추_가격_diff7_lag8', '배추_가격_diff7_lag35', '배추_가격_diff7_lag15', '배추_가격_diff7'} \n"'features_2week (총 21개)에서 제거된 피처 : 총 10개'"제거된 features : {'배추_가격_diff7_lag28', '배추_가격_EMA_7_pct', '배추_가격_diff7_lag1', '배추_가격_diff7_lag29', '배추_가격_diff7_lag24', '배추_가격_diff7_lag21', '배추_가격_diff7_lag8', '배추_가격_diff7_lag15', '배추_가격_diff7_lag7', '배추_가격_diff7_lag14'}"'features_4week (총 19개)에서 제거된 피처 : 총 10개'"제거된 features : {'배추_가격_EMA_7_pct', '배추_가격_diff7_lag1', '캠벨얼리_거래량_diff7_lag28', '배추_가격_EMA_28_pct', '배추_가격_diff7_lag15', '배추_가격_diff7_lag19', '샤인마스캇_거래량_diff7_lag28', '청상추_가격_diff7_lag28', '배추_가격_diff7_lag10', '배추_가격_diff7_lag14'}"
3) selectkbest에 의한 Feature Selection
※ SelectKBest: 기본 개념과 작동 원리
기본 개념 : SelectKBest는 주어진 특성 중에서 타겟 변수와 가장 잘 관련된 상위 K개의 특성을 선택하는 방법입니다. 이러한 특성 선택은 통계적 검정을 기반으로 하며, 여러 가지 score_func를 사용할 수 있습니다.
작동 원리
SelectKBest는 각 특성과 타겟 변수 간의 관계를 평가하는 함수(score_func)를 적용합니다. 이 함수를 통해 계산된 점수를 기반으로 각 특성을 순위 매깁니다. 가장 높은 점수를 받은 상위 K개의 특성을 선택합니다.
시계열 예측 문제와 같이 연속형 변수로 피처와 타겟이 구성된 회귀 문제에서는 주로 mutual_info_regression 또는 f_regression을 score_func로 사용합니다.
mutual_info_regression: 타겟 변수와 각 특성 간의 상호 정보량(mutual information)을 계산합니다.
f_regression: 타겟 변수와 각 특성 간의 F-통계를 계산하여 선형 관계를 평가합니다.
SelectKBest는 변수 선택을 수행하여, 이를 통해 모델의 성능을 향상시키거나 차원을 축소할 수 있습니다.
from sklearn.feature_selection import SelectKBest, mutual_info_regression,f_regression
# 1주차 예측을 위한 feature 갯수 선택
k_value_1week = int (len(features_1week)* 0.8)
selector_1week = SelectKBest(score_func=mutual_info_regression, k=k_value_1week) # k는 선택할 특성의 수
selector_1week.fit(train_1week[features_1week], train_1week['true_diff_1week'])
important_idx_1week = selector_1week.get_support()
kbest_features_1week = [feature for feature, is_important in zip(features_1week, important_idx_1week) if is_important]
# 2주차 예측을 위한 feature 갯수 선택
k_value_2week = int (len(features_2week)* 0.8)
selector_2week = SelectKBest(score_func=mutual_info_regression, k=k_value_2week) # k는 선택할 특성의 수
selector_2week.fit(train_2week[features_2week], train_2week['true_diff_2week'])
important_idx_2week = selector_2week.get_support()
kbest_features_2week = [feature for feature, is_important in zip(features_2week, important_idx_2week) if is_important]
# 4주차 예측을 위한 feature 갯수 선택
k_value_4week = int(len(features_4week) * 0.8)
selector_4week = SelectKBest(score_func=mutual_info_regression, k=k_value_4week) # k는 선택할 특성의 수
selector_4week.fit(train_4week[features_4week], train_4week['true_diff_4week'])
important_idx_4week = selector_4week.get_support()
kbest_features_4week = [feature for feature, is_important in zip(features_4week, important_idx_4week) if is_important]
display("kbest_features_1week : " + ", ".join(kbest_features_1week))
display("kbest_features_2week : " +", ".join(kbest_features_2week))
display("kbest_features_4week : " +", ".join(kbest_features_4week))'kbest_features_1week : 배추_가격, month, week, 배추_가격_diff7, 배추_가격_diff7_lag7, 배추_가격_diff7_lag8, 배추_가격_diff7_lag13, 배추_가격_diff7_lag14, 배추_가격_diff7_lag17, 배추_가격_diff7_lag21, 배추_가격_diff7_lag28, 배추_가격_diff7_lag35, 배추_가격_diff7_lag36, 배추_가격_diff7_lag40, 샤인마스캇_거래량_diff7_lag7, 캠벨얼리_거래량_diff7_lag7, 깻잎_가격_diff7_lag7, 시금치_가격_diff7_lag7, 배추_가격_EMA_7_pct, 배추_가격_EMA_14_pct, 배추_가격_EMA_28_pct''kbest_features_2week : 배추_가격, month, week, 배추_가격_diff7, 배추_가격_diff7_lag1, 배추_가격_diff7_lag7, 배추_가격_diff7_lag8, 배추_가격_diff7_lag14, 배추_가격_diff7_lag21, 배추_가격_diff7_lag28, 배추_가격_diff7_lag29, 배추_가격_diff7_lag33, 캠벨얼리_거래량_diff7_lag14, 시금치_가격_diff7_lag14, 배추_가격_EMA_14_pct, 배추_가격_EMA_28_pct''kbest_features_4week : 배추_가격, month, week, 배추_가격_diff7, 배추_가격_diff7_lag7, 배추_가격_diff7_lag14, 배추_가격_diff7_lag15, 청상추_가격_diff7_lag28, 캠벨얼리_거래량_diff7_lag28, 샤인마스캇_거래량_diff7_lag28, 시금치_가격_diff7_lag28, 샤인마스캇_가격_diff7_lag28, 토마토_가격_diff7_lag28, 배추_가격_EMA_14_pct, 배추_가격_EMA_28_pct'
4) SelectKBest 통해 제거된 피처 확인
deleted_features_1week = set(features_1week) - set(kbest_features_1week)
deleted_features_2week = set(features_2week) - set(kbest_features_2week)
deleted_features_4week = set(features_4week) - set(kbest_features_4week)
display(f'features_1week (총 {len(features_1week)}개)에서 제거된 피처 : 총 {len(deleted_features_1week)}개')
display(f'제거된 features : {deleted_features_1week} \n')
display(f'features_2week (총 {len(features_2week)}개)에서 제거된 피처 : 총 {len(deleted_features_2week)}개')
display(f'제거된 features : {deleted_features_2week}')
display(f'features_4week (총 {len(features_4week)}개)에서 제거된 피처 : 총 {len(deleted_features_4week)}개')
display(f'제거된 features : {deleted_features_4week}')'features_1week (총 27개)에서 제거된 피처 : 총 6개'"제거된 features : {'배추_가격_diff7_lag31', '배추_가격_diff7_lag1', '배추_가격_diff7_lag22', '배추_가격_diff7_lag2', '배추_가격_diff7_lag6', '배추_가격_diff7_lag15'} \n"'features_2week (총 21개)에서 제거된 피처 : 총 5개'"제거된 features : {'배추_가격_EMA_7_pct', '배추_가격_diff7_lag24', '배추_가격_diff7_lag6', '배추_가격_diff7_lag15', '배추_가격_diff7_lag10'}"'features_4week (총 19개)에서 제거된 피처 : 총 4개'"제거된 features : {'배추_가격_diff7_lag19', '배추_가격_EMA_7_pct', '배추_가격_diff7_lag1', '배추_가격_diff7_lag10'}"
10. 선택한 피처로 검증 성능 도출하기
SelectFromModel 이용한 선택한 피처 (sfm_features_1week,sfm_features_2week,sfm_features_4week), 혹은 SelectKBest를 이용하여 선택한 피처 (kbest_features_1week, kbest_features_1week,kbest_features_1week)를 성능 검증 함수 evaluate_model의 두번째 매개변수로 대입하여 성능 검증을 합니다.
features_date = [f'{item_selected}_가격', 'month', 'week']
score_1week, pred_1week, model_1week = evaluate_lgbm_model(
item_selected, train_1week, features_date, start_date_valid, n_week=1, nmae_function=nmae, train_update_mode='daily'
)
score_2week, pred_2week, model_2week = evaluate_lgbm_model(
item_selected, train_2week, features_date, start_date_valid, n_week=2, nmae_function=nmae, train_update_mode='daily'
)
score_4week, pred_4week, model_4week = evaluate_lgbm_model(
item_selected, train_4week, features_date, start_date_valid, n_week=4, nmae_function=nmae, train_update_mode='daily'
)
score_mean = (score_1week + score_2week + score_4week) / 3
display(f'mean nmae score : {score_mean} ({score_1week},{score_2week},{score_4week})')100%|██████████| 143/143 [00:01<00:00, 106.34it/s]
100%|██████████| 136/136 [00:01<00:00, 105.67it/s]
100%|██████████| 122/122 [00:01<00:00, 105.51it/s]
'mean nmae score : 0.20327784983619337 (0.18593863509282854,0.22477496830776467,0.19911994610798694)
11. Optuna를 사용한 하이퍼파라미터 탐색
※ Optuna
Optuna는 하이퍼파라미터 최적화 라이브러리로, 기계 학습 모델의 성능을 향상시키기 위해 최적의 하이퍼파라미터 조합을 자동으로 탐색하는 데 사용됩니다.
Optuna는 목표 함수를 최소화하거나 최대화하는 방향으로 하이퍼파라미터 공간을 탐색하며, 이를 통해 데이터 과학 및 기계 학습 모델 개발 과정을 효율적으로 진행할 수 있도록 도와줍니다.
※ Optuna를 사용한 하이퍼파라미터 탐색 일반적인 코드 적용 방법
Optuna 스터디 객체 생성 : Optuna를 사용하려면 먼저 스터디(Study) 객체를 생성해야 합니다. 스터디 객체는 하이퍼파라미터 탐색을 관리하고 실행합니다. 탐색 방향을 최소화(minimize) 또는 최대화(maximize)로 설정할 수 있습니다.

import optuna
from functools import partial
def objective(trial, item_selected, train_week, features_week, start_date_valid, n_week, nmae_function=nmae):
# 하이퍼파라미터 탐색 대상
max_depth = trial.suggest_int('max_depth', 2, 10)
learning_rate = trial.suggest_float('learning_rate', 0.001, 0.1)
num_leaves = trial.suggest_int('num_leaves', 3, 10)
# 튜닝된 파라미터로 evaluate_lgbm_model 함수 호출
score, _, _ = evaluate_lgbm_model(
item_selected,
df=train_week,
features=features_week,
start_date=start_date_valid,
n_week=n_week,
nmae_function=nmae,
# 추가로 LGBM 파라미터 넣을 수 있음
model_params={
'learning_rate': learning_rate,
'num_leaves': num_leaves,
'max_depth': max_depth
}
)
return score
# Optuna를 사용하여 하이퍼파라미터 탐색
study_1week = optuna.create_study(direction='minimize')
study_1week.optimize(
partial(objective, item_selected=item_selected, train_week=train_1week, features_week=sfm_features_1week,
start_date_valid=start_date_valid, n_week=1, nmae_function=nmae),
n_trials=20
)
study_2week = optuna.create_study(direction='minimize')
study_2week.optimize(
partial(objective, item_selected=item_selected, train_week=train_2week, features_week=sfm_features_2week,
start_date_valid=start_date_valid, n_week=2, nmae_function=nmae),
n_trials=20
)
study_4week = optuna.create_study(direction='minimize')
study_4week.optimize(
partial(objective, item_selected=item_selected, train_week=train_4week, features_week=sfm_features_4week,
start_date_valid=start_date_valid, n_week=4, nmae_function=nmae),
n_trials=20
)
# 최적의 하이퍼파라미터 값 출력
best_params_1week = study_1week.best_params
print("Best Params of 1week predict model :", best_params_1week)
best_params_2week = study_2week.best_params
print("Best Params of 2week predict model :", best_params_2week)
best_params_4week = study_4week.best_params
print("Best Params of 4week predict model :", best_params_4week)Best Params of 1week predict model : {'max_depth': 10, 'learning_rate': 0.003894280187206379, 'num_leaves': 6}
Best Params of 2week predict model : {'max_depth': 5, 'learning_rate': 0.0051628110827738605, 'num_leaves': 5}
Best Params of 4week predict model : {'max_depth': 6, 'learning_rate': 0.004377442857471464, 'num_leaves': 10}13. test 데이터에 동일한 전처리 및 feature engineering
def processing_test(base_train, test, significant_diff_lags_all_weeks, features_other_item, features_items):
features_1week = features_items[0]
features_2week = features_items[1]
features_4week = features_items[2]
start_date_test = test['date'].min()
test_prep = pd.concat([base_train,test]).reset_index(drop=True)
test_prep['month'] = test_prep['date'].dt.month
test_prep['week'] = test_prep['date'].dt.isocalendar().week.astype(np.int32)
test_prep['weekday'] = test_prep['date'].dt.weekday
# 지연 차분 피처 생성하기
for diff_lag in list(significant_diff_lags_all_weeks):
if diff_lag == 0:
test_prep[f'{item_selected}_가격_diff7'] = test_prep[f'{item_selected}_가격'].copy().diff(7)
else:
test_prep[f'{item_selected}_가격_diff7_lag{diff_lag}'] = train_selected[f'{item_selected}_가격'].copy().diff(7).shift(diff_lag)
# 타품목 차분 피처 생성하기
for features_other_item in features_other_item:
for feature in features_other_item:
feature_split = feature.split('_')
feature_name = feature_split[0] + '_' + feature_split[1]
n_lag = int(feature_split[3][-1])
test_prep[feature] = test_prep[feature_name].diff(n_lag)
# 가중이동평균과의 변화율 피처 생성하기
for window_size in [7,14,28]:
ema_column = f'{item_selected}_가격_EMA_{window_size}'
test_prep[ema_column] = test_prep[f'{item_selected}_가격'].ewm(span=window_size, adjust=False).mean()
# 퍼센트 변동율 계산
ema_pct_column = f'{item_selected}_가격_EMA_{window_size}_pct'
test_prep[ema_pct_column] = ((test_prep[f'{item_selected}_가격'] - test_prep[ema_column]) / test_prep[ema_column]) * 100
test_prep = test_prep.dropna().reset_index(drop=True)
test_prep = test_prep[test_prep['date'] >= start_date_test].reset_index(drop=True)
test_1week = test_prep[ ['date'] + features_1week ]
test_2week = test_prep[ ['date'] + features_2week ]
test_4week = test_prep[ ['date'] + features_4week ]
return test_1week, test_2week, test_4week
test['date'] = pd.to_datetime(test['date'])
features_other_items = [features_other_item_1week, features_other_item_2week, features_other_item_4week]
sfm_features_items = [ sfm_features_1week,sfm_features_2week,sfm_features_4week ]
test_1week, test_2week, test_4week = processing_test(train.tail(50), test.iloc[0:1], significant_diff_lags_all, features_other_items, sfm_features_items)
display(test['date'].min(),test['date'].max())
display(test_1week)
display(test_2week)
display(test_4week)
14. test 기간1주, 2주, 4주 후의 품목 가격 예측 및 최종 제출 파일 생성
item_submission = pd.DataFrame(columns=['예측대상일자', f'{item_selected}_가격(원/kg)'])
test_day_lst = test['date'].to_list()
model_1week = lgb.LGBMRegressor(**best_params_1week, silent=True, verbosity=-1)
model_1week.fit(train_1week[sfm_features_1week], train_1week['true_diff_1week'])
model_2week = lgb.LGBMRegressor(**best_params_2week, silent=True, verbosity=-1)
model_2week.fit(train_2week[sfm_features_2week], train_2week['true_diff_2week'])
model_4week = lgb.LGBMRegressor(**best_params_4week, silent=True, verbosity=-1)
model_4week.fit(train_4week[sfm_features_4week], train_4week['true_diff_4week'])
# 매일 마다 데이터 갱신
for idx, date in tqdm(enumerate(test_day_lst), total=len(test_day_lst)):
test_updated = test[test['date'] <= date]
_last_item_price = test_updated[f'{item_selected}_가격'].values[-1]
sfm_features_items = [sfm_features_1week, sfm_features_2week, sfm_features_4week]
test_1week,test_2week,test_4week = processing_test(train.tail(50), test_updated, significant_diff_lags_all, features_other_items,sfm_features_items)
predict_1week_date = date + pd.Timedelta(weeks=1)
if (predict_1week_date.weekday() != 6):
y_pred_diff_1week = model_1week.predict(test_1week[sfm_features_1week].iloc[-1:])[0]
y_pred_week1 = y_pred_diff_1week + _last_item_price
else:
y_pred_week1 = 0.0
predict_2week_date = date + pd.Timedelta(weeks=2)
if (predict_2week_date.weekday() != 6):
y_pred_diff_2week = model_2week.predict(test_2week[sfm_features_2week].iloc[-1:])[0]
y_pred_week2 = y_pred_diff_2week + _last_item_price
else:
y_pred_week2 = 0.0
# 일요일은 예측값을 0 가격으로 변경
predict_4week_date = date + pd.Timedelta(weeks=4)
if (predict_4week_date.weekday() != 6):
y_pred_diff_4week = model_4week.predict(test_4week[sfm_features_4week].iloc[-1:])[0]
y_pred_week4 = y_pred_diff_4week + _last_item_price
else:
y_pred_week4 = 0.0
submission = pd.DataFrame(columns=['예측대상일자', f'{item_selected}_가격(원/kg)'])
submission['예측대상일자'] = [f'{date}+1week', f'{date}+2week', f'{date}+4week']
submission.loc[0, f'{item_selected}_가격(원/kg)'] = np.round(y_pred_week1,1)
submission.loc[1, f'{item_selected}_가격(원/kg)'] = np.round(y_pred_week2,1)
submission.loc[2, f'{item_selected}_가격(원/kg)'] = np.round(y_pred_week4,1)
item_submission = pd.concat([item_submission, submission]).reset_index(drop=True)
display(item_submission)
item_submission.to_csv(f"submission_{item_selected}.csv", index = False)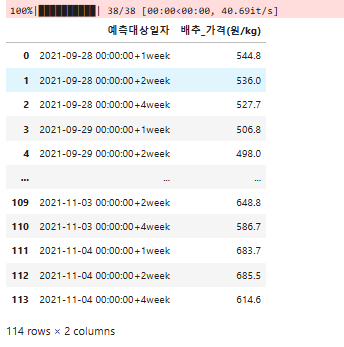
15. 8개 품목의 예측 결과를 하나의 Submission 파일로 합쳐 제출하기
# '가격'이 포함된 열 이름에서 품목 이름을 추출
item_list = [col.split('_')[0] for col in train.columns[1:] if '가격' in col]
final_submission = None
# 각 품목에 대한 예측 결과를 하나의 데이터 프레임으로 합침
for idx, item in enumerate(item_list):
filename = f'submission_{item}.csv'
submission_item = pd.read_csv(filename)
if idx == 0:
final_submission = submission_item
else:
# 첫번째 열을 제외한 나머지 열만 추가
final_submission = pd.concat([final_submission, submission_item.iloc[:, 1]], axis=1)
display(final_submission.head(20))
'딥러닝 > 딥러닝: 실전 프로젝트 학습' 카테고리의 다른 글
| 시계열 : 서울시 평균기온 예측 프로젝트 2(시각화 분석) (0) | 2025.02.03 |
|---|---|
| 시계열 : 서울시 평균기온 예측 프로젝트 1(데이터 이해) (0) | 2025.02.02 |
| 시계열 : 농산물 가격 예측 프로젝트 5 (LightGBM을 활용한 시계열 예측) (0) | 2025.01.31 |
| 시계열 : 농산물 가격 예측 프로젝트 4 (ARIMA 모델을 활용한 시계열 예측 기초와 적용) (0) | 2025.01.30 |
| 시계열 : 농산물 가격 예측 프로젝트 3 (데이터 전처리와 시계열 정상성(Stationarity)) (0) | 2025.01.30 |