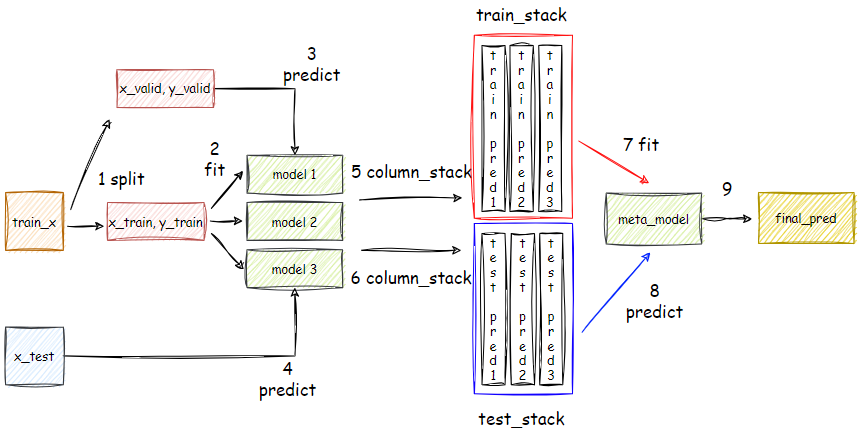
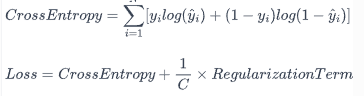1. 스태킹(Stacking) 스태킹(Stacking) 은 앙상블 학습의 한 방법으로, 여러 가지 모델의 예측 결과를 결합하여 최종적인 예측을 만드는 기법입니다.스태킹의 핵심 아이디어는 n개의 개별 모델들의 예측값을 새로운 특성으로 사용하여 최종 예측을 수행하는 1개의 메타 모델(meta model)을 학습하는 것입니다. ※ 스태킹의 장점스태킹은 여러 모델의 강점을 결합하여 전반적인 예측 성능을 향상시키는 데 도움을 줍니다.※ 스태킹의 주의점여러 모델을 학습시키고 예측을 수행해야 하므로 계산 비용이 높을 수 있습니다.본 모델들의 예측 결과를 기반으로 메타 모델이 다시 예측을 수행하기 때문에, 과적합의 위험이 있습니다.2. 스태킹 코드2.1 데이터 준비import pandas as pdfrom sklea..