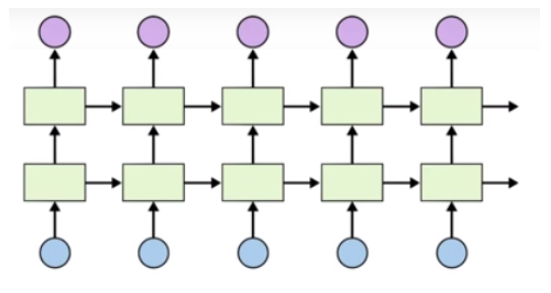
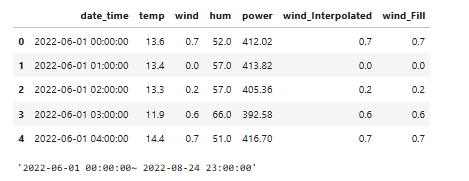
1. 심층(Staked) LSTM1) 개요Stacked LSTM은 여러 개의 LSTM 층을 쌓아올린 심층 구조의 LSTM 모델입니다.기본적인 LSTM은 단일 층으로 이루어져 있지만, Stacked LSTM은 여러 개의 LSTM 층을 수직으로 쌓아 심층 구조를 형성합니다.각 LSTM 층의 출력이 다음 층의 입력으로 전달되며, 이를 통해 더욱 복잡하고 추상적인 특징을 학습할 수 있습니다.이는 모델이 입력 데이터를 더욱 효과적으로 처리하고, 다양한 패턴을 포착할 수 있게 해줍니다.※ Stacked LSTM의 구조Stacked LSTM의 구조는 다음과 같습니다.각 시점의 입력 데이터는 첫 번째 LSTM 층으로 전달됩니다.첫 번째 층의 출력은 두 번째 LSTM 층의 입력으로 사용되며, 이러한 방식으로 최종 LST..