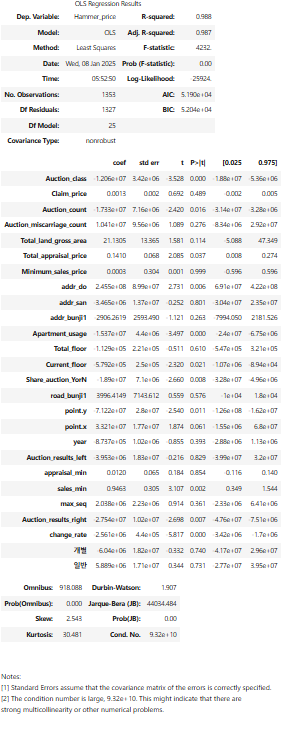
1. 데이터 로드import pandas as pdtrain = pd.read_csv('train.csv')test = pd.read_csv('test.csv')result = pd.read_csv('Auction_result.csv')submission = pd.read_csv('sample_submission.csv') 2. 학습(train) 데이터 전처리# year 피처 생성 및 날짜 피처 제거train['Final_auction_date'] = pd.to_datetime(train['Final_auction_date'], errors = 'ignore')train['year'] = train['Final_auction_date'].dt.yeardate_col = ['Appraisal_date', ..