1. 피처 중요도(Feature Importance)
피처 중요도는 머신러닝에서 각 피처가 모델의 예측에 얼마나 중요한지를 나타내는 척도입니다.
이는 모델이 결정을 내리는데 있어 각 피처가 얼마나 많은 영향을 미치는지 평가하는 것으로, 피처 중요도를 통해 어떤 피처들이 예측 변수에 가장 큰 영향을 미치는지 이해할 수 있습니다.
2. 의사 결정 나무( Decision Tree Model ) 기반 모델과 피처 중요도 측정
의사 결정 나무는 데이터를 분석하여 데이터 사이의 패턴을 학습하고, 나무 모양의 구조를 사용해 예측을 수행하는 머신러닝 모델입니다.
간단히 말해서, 의사 결정 나무는 일련의 질문을 통해 데이터를 분류하거나 값을 예측합니다.
이 질문들은 데이터의 피처에 기반하여 설정되며, 각 질문은 예 또는 아니오로 답할 수 있습니다.
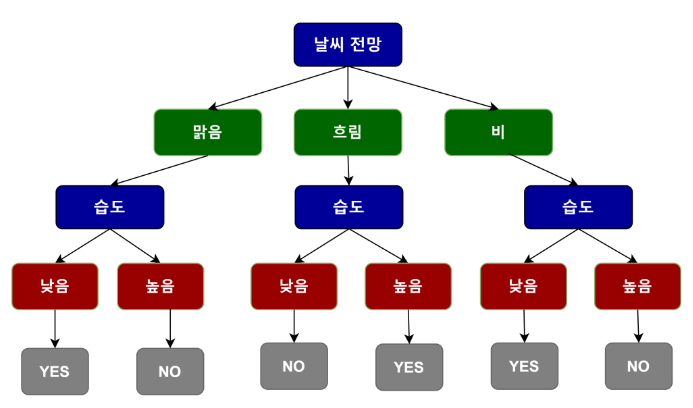
이 모델은 가지를 따라가면서 데이터를 점점 더 작은 그룹으로 나눕니다.
각 분할은 데이터를 더 잘 이해하고, 최종적으로는 예측을 수행할 수 있도록 도와줍니다.
나무의 가장 윗부분을 루트라고 하며, 끝부분을 잎 또는 결정 노드 라고 합니다.
각 결정 노드는 예측 결과를 나타냅니다.
의사 결정 나무에서 각 피처의 중요도는 그 피처가 결정 나무를 구성하는데 얼마나 중요한지를 나타냅니다.
특정 피처를 기준으로 데이터를 분할 할때, 이 분할이 얼마나 좋은 분할인지 평가하여 피처의 중요도를 측정합니다.
좋은 분할이란, 각 그룹의 데이터가 비슷한 특성을 가지게 되는 분할을 의미합니다.
즉, 피처가 데이터를 잘 나누는 데 도움이 될수록, 그 피처의 중요도는 높아집니다.
2.1 데이터 로드
import pandas as pd
from sklearn.tree import DecisionTreeRegressor
housing_df = pd.read_csv('californial_housing.csv')
housing_df.head()
2.2 DecisionTreeRegressor 모델 객체의 피처 중요도 얻기
# 피처와 타겟 변수 분리
X = housing_df.drop('target', axis=1)
y = housing_df['target']
model_dt = DecisionTreeRegressor(random_state=42)
model_dt.fit(X, y)
# 피처 중요도 추출
feature_importances_dt = model_dt.feature_importances_
display(feature_importances_dt)
# feature_importances와 X.columns을 이용하여 중요도가 높은 순서로 정렬하여 출력
df_feature_importances_dt = pd.DataFrame({'Feature': X.columns, 'Importance': feature_importances_dt})
sorted_df_feature_importances_dt = df_feature_importances_dt.sort_values(by='Importance', ascending=False).reset_index(drop=True)
display(sorted_df_feature_importances_dt)
2.3 피처 중요도 시각화
import matplotlib.pyplot as plt
# 피처 중요도를 수직 바 그래프로 시각화
fig, ax = plt.subplots(figsize=(8, 4))
ax.bar(X.columns, feature_importances_dt, color='skyblue')
ax.set_xlabel("Feature")
ax.set_ylabel("Feature Importance")
ax.set_title("Feature Importance in Decision Tree Model")
plt.tight_layout() # 레이블이 잘리지 않도록 조정
plt.show()
3. 선형 모델 기반의 피처 중요도
선형 모델은 데이터의 피처와 타겟 변수 간의 관계를 선형 방정식을 통해 모델링합니다.
이 모델에서 피처의 중요도는 각 피처의 가중치를 통해 평가됩니다.
가중치의 절대값이 클수록 피처의 중요도가 높다고 볼 수 있습니다.
선형 모델을 사용할 때, 중요한 것은 데이터의 스케일링입니다.
선형 모델은 가중치를 통해 피처의 중요도를 결정하기 때문에, 피처간의 스케일 차이가 모델 성능에 큰 영향을 미칠 수 있습니다.
따라서, 모든 피처를 동일한 범위나 분포로 조정하기 위해 데이터를 스케일링하는 것이 필요합니다.
3.1 DecisionTreeRegressor 모델 객체의 피처 중요도
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
# 피처 스케일링
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 스케일링된 데이터로 선형 회귀 모델 학습
model_lr_scaled = LinearRegression()
model_lr_scaled.fit(X_scaled, y)
# 피처의 가중치를 피처 중요도로 사용 (스케일링된 모델)
feature_importances_lr = abs(model_lr_scaled.coef_)
feature_importances_lrarray([0.96849035, 0.23637448, 0.33845237, 0.15501547, 0.06306794,
0.26386702])
3.2 피처중요도 시각화
import matplotlib.pyplot as plt
# 피처 중요도를 수직 바 그래프로 시각화
fig, ax = plt.subplots(figsize=(8, 4))
ax.bar(X.columns, feature_importances_lr, color='skyblue')
ax.set_xlabel("Feature")
ax.set_ylabel("Feature Importance")
ax.set_title("Feature Importance in LinearRegression Model")
plt.tight_layout() # 레이블이 잘리지 않도록 조정
plt.show()
'머신러닝 > 머신러닝: 심화 내용' 카테고리의 다른 글
| LightGBM 모델 (0) | 2024.12.25 |
|---|---|
| 피처 선택(Feature Selection) (0) | 2024.12.24 |
| 피처 생성(Feature Generation) 2 : 다항식 피처 생성 (0) | 2024.12.24 |
| 피처 생성(Feature Generation) 1 : Binning 기법 (0) | 2024.12.23 |
| 분류 모델 하이퍼파라미터 튜닝 (0) | 2024.12.22 |