1. 모델 학습과 최적화: 가중치 조정과 예측 정확도 향상
신경망이 학습하는 과정을 단계별로 살펴보겠습니다.
- 최초 가중치 설정: 처음에는 가중치를 임의로 설정합니다. 예를 들어, 집 크기의 가중치를 100, 방의 가중치를 10으로 설정해보겠습니다.
- 가중치와 입력값으로 예측값 계산: 이제 이 가중치를 사용해서 예측을 해봅니다. 만약 첫 번째 집의 크기가 30, 방의 개수가 2개라면, 우리의 예측 가격은 30 x 100 + 2 x 10 = 3,020이 됩니다.
- 예측값과 실제값의 차이 계산: 그런데, 이 집의 실제 가격은 3,000입니다.. 우리의 예측과 20만큼 차이가 납니다.
- 가중치 조정으로 차이 줄이기: 이제 가중치를 조정해보겠습니다. 집 크기의 가중치를 90으로, 방의 가중치를 150로 조정해보겠습니다. 그러면 새로운 계산은 30 x 90 + 2 x 150 = 3,000이 됩니다.
- 예측 가격과 실제 가격 일치: 이제 우리의 계산은 실제 가격과 정확히 맞아떨어집니다. 가중치를 조정함으로써 모델을 개선한 것 입니다.
이렇게 모델은 집의 특성을 바탕으로 가격을 예측하고, 실제 가격과의 차이를 통해 가중치를 조정합니다.
이 과정을 반복하면서 모델은 점점 더 정확한 예측을 하게 됩니다.
하지만, 집 가격을 예측하는 데 있어서 모든 집들에 대해 정확히 맞추는 건 좀 더 복잡한 일입니다.
왜냐하면 각각의 집마다 예측에서 벗어난 정도, 즉 오류가 다르기 때문입니다.
이럴 때 이 모든 오류들을 한 번에 볼 수 있는 방법이 필요랍니다.
여기서 손실 함수라는 것이 등장합니다.
손실 함수는 모든 오류들을 점수로 환산해 줍니다.
가장 흔히 쓰이는 손실 함수 중 하나는 평균 제곱 오류라고 해서, 각 오류를 제곱한 다음에 그 평균을 내는 방식입니다.
이렇게 하면 큰 오류에 더 많은 점수를 부여하여, 모델이 더 심각한 오류에 더 집중할 수 있도록 도와줍니다.
2.가중치 조정을 통한 신경망의 예측 오차 최소화
input_data = [30, 2] # 입력 데이터
target_actual = 3000 # 실제 목표값
weights_0 = {'node_0': [100, 10]} # 첫 번째 가중치 설정
# 첫 번째 가중치를 사용한 예측값
output_0 = input_data[0] * weights_0['node_0'][0] + input_data[1] * weights_0['node_0'][1]
error_0 = output_0 - target_actual # 오차
# 가중치 조정 및 두 번째 예측
weights_1 = {'node_0': [90, 150]} # 두 번째 가중치 설정 (가중치 조정)
output_1 = input_data[0] * weights_1['node_0'][0] + input_data[1] * weights_1['node_0'][1]
error_1 = output_1 - target_actual
print("첫 번째 예측 오차:", error_0)
print("조정된 가중치로의 예측 오차:", error_1)첫 번째 예측 오차: 20
조정된 가중치로의 예측 오차: 03. 경사하강법: 모델 최적화를 위한 핵심 전략
우리가 어떻게 모델을 더욱 똑똑하게 만들려면 경사 하강법이라는 방법이 여기에 답이 될 거예요.
이 방법을 이해하려면, 산에서 내려오는 상상을 해보면 됩니다.
가장 낮은 곳을 찾으려는 노력이 바로, 우리의 컴퓨터 프로그램이나 앱이 데이터를 가장 잘 이해하고, 가장 효율적으로 일할 수 있는 최적의 상태를 찾는 과정과 같습니다.
이를 위해 우리는 가중치라는 것을 조절해요.
가중치는 프로그램의 정보 처리 방식을 세밀하게 조절해 주는 조절기 와 같습니다.
가중치를 어떻게 조절하느냐에 따라 프로그램이 정보를 어떻게 처리하고, 결론을 내리는지가 달라집니다.
산을 내려올 때, 우리는 발 아래의 경사를 느끼며 어디로 내려가야 할지 결정합니다.
이 경사가 바로 기울기, 수학에서는 도함수라고 부르는 것과 같은 원리입니다.
이 기울기를 사용해 가중치를 조금씩 조절하면서, 우리의 프로그램을 최고의 성능으로 이끌 수 있습니다.
기울기가 양수면, 가중치를 줄여야 하고, 음수면 가중치를 늘려야 합니다.
매 순간 기울기를 확인하며, 최적의 점을 찾아가는 것입니다.
산에서 내려올 때는 안전하게, 그리고 천천히 내려가야 하듯이, 우리도 가중치를 조정할 때는 신중하게, 그리고 차분히 접근해야 합니다.
가끔은 잘못된 방향으로 조금씩 벗어날 수도 있지만, 결국에는 가장 낮은 지점, 즉 가장 작은 오류를 갖는 지점에 도달할 수 있습니다.
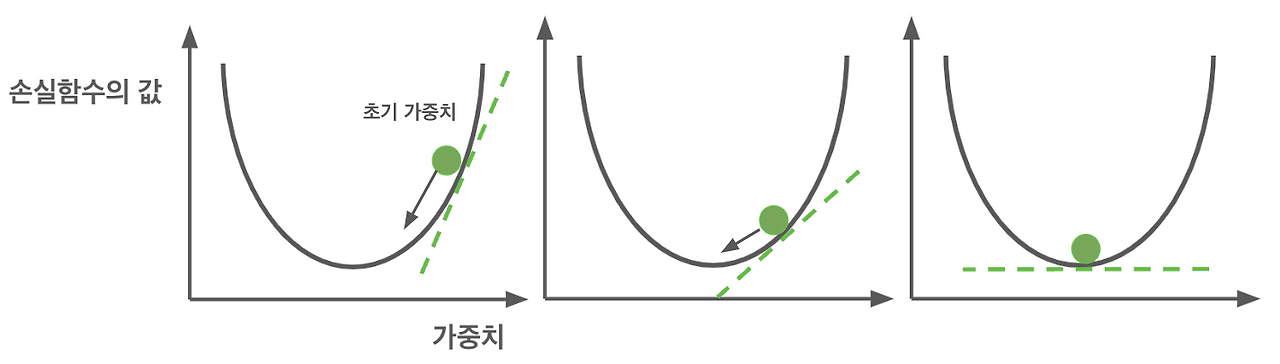
그렇다면 가중치를 어느 방향으로, 얼마나 조절해야 하는지는 손실 함수의 기울기가 바로 그 답을 알려줍니다.
이 기울기는 손실을 최소화하기 위해 가중치를 증가시켜야 할지, 감소시켜야 할지를 알려주는 지표입니다.
그리고 학습률은 이 기울기의 영향을 얼마나 반영할지를 조절하는 역할을 합니다.
이 학습률을 조절함으로써, 우리는 학습의 속도와 안정성을 조절 할 수 있습니다.
일반적으로는 손실 함수의 기울기에 학습률을 곱한 값을 현재 가중치에서 빼주어 가중치를 업데이트하는데, 이렇게 하는 이유는 손실 함수의 기울기가 가리키는 방향으로 가중치를 조정함으로써, 손실 함수의 값을 줄이고 최적의 모델 성능에 도달하고자 하기 때문입니다.
학습률은 마치 우리가 산을 내려올 때 조심스럽게 한 걸음 한 걸음 내딛는 것과 같습니다.
너무 큰 학습률은 모델을 불안정하게 만들 수 있고, 너무 작으면 학습이 더디게 될 수 있습니다.
그래서 우리는 '딱 좋은' 학습률을 찾아야 합니다.
이 '딱 좋은' 학습률을 찾아내는 것도 모델을 훈련하는 중요한 부분입니다.
정리하자면, 경사 하강법은 우리가 모델의 가중치를 최적화하기 위해 사용하는 방법입니다.
손실 함수의 기울기를 계산하여 가중치를 조절하고, 학습률을 통해 그 조절의 정도를 결정함으로써 점점 더 정확한 예측을 할 수 있는 모델로 나아갈 수 있습니다.
그리고 그 결과는 바로 더 나은 결정, 더 정확한 예측, 그리고 더 효율적인 알고리즘입니다.
4. 손실 함수의 기울기 계산과 가중치 업데이트(ReLu)
손실 함수의 기울기를 계산하여 가중치를 조절하고, 학습률을 통해 그 조절의 정도를 결정함으로써, 우리는 점점 더 정확한 예측을 할 수 있는 모델로 나아갈 수 있습니다.
손실 함수의 기울기를 계산하여 가중치를 조절하고, 학습률을 통해 그 조절의 정도를 결정하는 것은 마치 '오류를 바로잡아 나가는 과정' 과 같습니다.
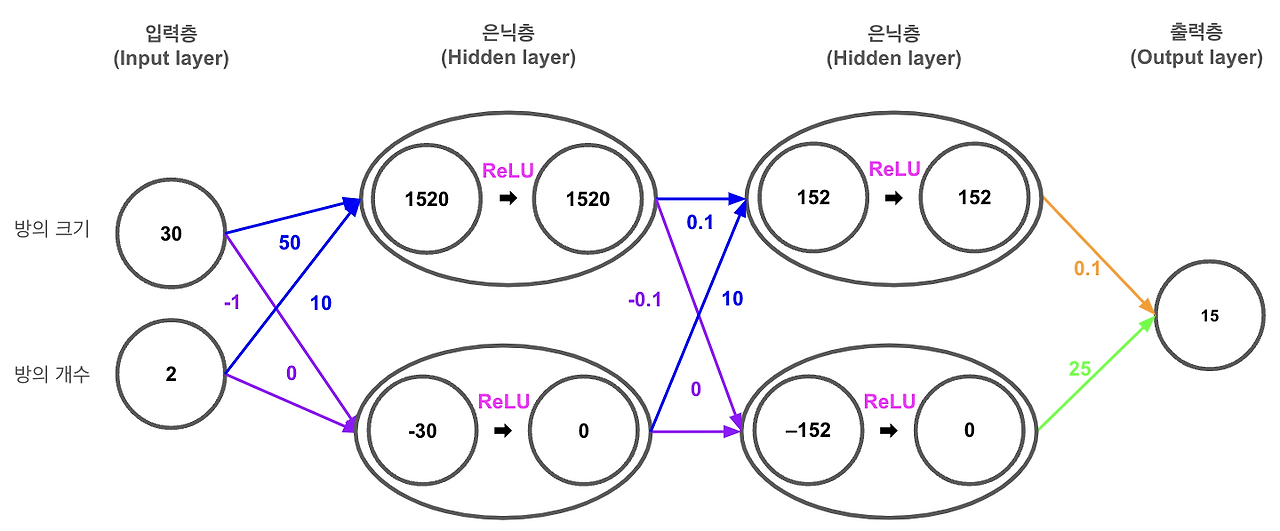
위 이미지를 보면 이 신경망은 두 개의 입력 노드, 두 개의 은닉층 노드, 그리고 하나의 출력 노드로 구성되어 있습니다.
우리의 목표는 신경망이 18이라는 실제 목표값을 예측하도록 만드는 것 입니다.
그래서 우리는 이런 과정을 거치게 됩니다.
- 오차 계산하기: 신경망이 15라고 예측했습니다. 하지만 우리가 원하는 정답은 18입니다. 이 둘 사이의 차이를 손실 이라고 부르는데, 이것은 우리 모델이 얼마나 정답에서 벗어났는지를 나타냅니다. 여기서 손실은 18에서 15을 빼서 3이 됩니다.
- 예측값에 대한 오류의 기울기 계산: 우리는 손실 함수로 평균 제곱 오차(MSE)를 사용하겠습니다. MSE를 미분하면 예측값과 실제값의 차이에 2를 곱한 값이 나옵니다. 그러니까 여기서는 -3에 2를 곱해서 -6이 나오게 됩니다.
- 가중치에 대한 손실 함수의 기울기: 손실 함수의 기울기를 가중치까지 전달하려면, 활성화 함수인 ReLU를 거쳐야 합니다. ReLU는 간단하게 말해서 음수면 0으로 만들고, 양수면 그대로 둡니다. 이미지에서 첫 번째 은닉층 노드는 152로 양수니까 변화 없고, 두 번째 은닉층 노드는 0이 되었습니다. 그럼 첫 번째 은닉층 노드의 값 152에 -6을 곱해 가중치에 대한 기울기를 계산하면 -912가 나오게 됩니다.
- 업데이트할 가중치 계산하기: 이제, 우리가 가중치를 얼마나 조정할지 결정해야 합니다. 이때 중요한 역할을 하는 것이 바로 학습률(learning rate)입니다. 학습률은 가중치 조정의 정도를 결정합니다. 너무 크면 가중치가 크게 변해 모델이 목표값을 빠져나갈 수 있고, 너무 작으면 거의 변하지 않아 학습이 제대로 이루어지지 않을 수 있습니다. 그래서 적절한 학습률을 설정하는 것이 정말 중요합니다.
- 이번 예시의 경우 학습률을 0.01로 설정했어요. 가중치에 대한 손실 함수의 기울기(-912)에 학습률(0.01)을 곱한 값을 이전 가중치에서 빼주어 새로운 가중치를 계산합니다. 즉, 가중치 업데이트 공식은 새로운 가중치 = 이전 가중치 - (학습률 * 기울기)가 됩니다. 이 경우, -912에 0.01을 곱한 값은 -9.12이며, 이 값을 이전 가중치(0.1)에서 빼서 새로운 가중치(9.22)를 계산합니다.
이렇게 새로운 값으로 가중치를 업데이트하고, 이 과정을 여러 번 반복하면서, 신경망은 점점 더 실제 목표값인 18에 가까운 예측을 하게 됩니다.
5. ReLU 활성화 함수를 활용한 가중치 업데이트
1) 오차 계산하기
신경망이 예측한 값(predicted_value)과 실제 목표값(target_value) 사이의 차이를 계산하여 오차를 도출합니다.
이 오차는 신경망의 현재 성능을 나타내며, 학습 과정에서 이 오차를 최소화하는 것이 목표입니다.
2) 예측값에 대한 오류의 기울기 계산:
오차의 기울기를 계산합니다. 여기서는 평균 제곱 오차(MSE)의 미분값을 사용하는데, 이는 오차를 줄이려 합니다.
이 기울기는 가중치 업데이트 시 오차를 어떻게 줄여야 할지 방향을 제공합니다.
3) 가중치에 대한 손실 함수의 기울기
- 은닉층 노드의 출력값에 대해 ReLU 활성화 함수의 미분을 적용합니다. ReLU의 미분은 출력값이 0보다 클 때 1이고, 그렇지 않을 때 0입니다. 이는 가중치 조정 시 활성화 함수를 포함한 값이 업데이트에 기여하는 정도를 결정합니다.
- 가중치에 대한 손실 함수의 기울기는 은닉층 노드의 출력값, 활성화 함수 결과, 그리고 ReLU 미분값의 곱으로 계산됩니다.
4)다음 가중치 계산하기
- 학습률(learning_rate)과 가중치에 대한 손실 함수의 기울기를 사용하여 다음 가중치 값을 계산합니다. 학습률은 가중치 조정의 크기를 결정하며, 일반적으로 작은 값으로 설정됩니다. 계산된 가중치는 새로운 학습 단계에서 신경망의 성능 개선에 다시 사용됩니다.
def relu_derivative(output):
"""ReLU 함수의 미분값"""
return 1 if output > 0 else 0
# 1. 오차 계산하기
predicted_value = 15
target_value = 18
error = predicted_value - target_value
# 2. 예측값에 대한 오류의 기울기 계산
error_gradient = 2 * error
# 두 번째 은닉층 노드의 출력값
hidden_node_output = 152 # ReLU를 거친 후의 값
# 3. 가중치에 대한 손실 함수의 기울기
hidden_node_gradient = relu_derivative(hidden_node_output)
weight_gradient = hidden_node_output * error_gradient * hidden_node_gradient
# 4. 다음 가중치 계산하기
learning_rate = 0.01
next_weight = 0.1 - learning_rate * weight_gradient
print(f"업데이트된 가중치 값: {next_weight}")업데이트된 가중치 값: 9.226. 역전파 과정: 복잡한 딥러닝 모델의 가중치 최적화
역전파는 출력층에서부터 시작해서 입력층으로 되돌아가는 과정입니다.
이 과정은 마치 우리가 실수를 하면서 그 실수에서 배우는 것과 비슷합니다.
모델도 자기가 예측에서 범한 작은 실수들을 돌아보고, 그걸 바탕으로 더 나은 예측을 위해 배워나갑니다.
역전파를 할 때, 우리는 신경망의 각 구간에서 발생한 오차, 즉 오류가 각 가중치에 얼마나 영향을 미치는지 를 계산합니다. 이를 위해 오차의 크기, 오차가 발생한 구간의 가중치, 그리고 활성화 함수가 어떻게 반응하는지를 봅니다.
이 모든 정보를 바탕으로 가중치를 조금씩 조정해 나가면서, 신경망은 점점 더 정확해집니다.
오류의 크기, 손실 함수의 기울기를 계산하고, 그걸 바탕으로 가중치를 어떻게 조정해야 할지를 결정 했던 그 모든 단계들이 바로 역전파의 일부입니다.
이 과정을 통해, 우리의 모델은 실수에서 배우며 점점 더 나아집니다.
역전파는 신경망이 복잡한 문제들을 해결하며, 정확한 예측을 할 수 있도록 돕는 핵심적인 과정입니다.
우리가 순방향 전파로 예측을 하고, 그 다음에 실수를 바탕으로 역전파를 통해 가중치를 조정하는 이 과정을 반복하면서, 모델은 점차 완성도를 높여가게 됩니다.
1) 역전파 과정: 신경망을 통한 집 가격 예측 모델 구현
def relu(x):
"""ReLU 활성화 함수"""
return max(0, x)
def relu_derivative(output):
"""ReLU 함수의 미분값"""
return 1 if output > 0 else 0
# 입력 데이터 설정
input_data = [30.0, 2.0]
# 가중치 설정
weights = {
'hidden1_node0': [50.0, 10.0],
'hidden1_node1': [-1.0, 0.0],
'hidden2_node0': [0.1, 10.0],
'hidden2_node1': [-0.1, 0.0],
'output': [0.1, 25.0]
}
# 첫 번째 은닉층 계산 및 ReLU 활성화 함수 적용
hidden1_node0_output = input_data[0] * weights['hidden1_node0'][0] + input_data[1] * weights['hidden1_node0'][1]
hidden1_node0_activated = relu(hidden1_node0_output)
hidden1_node1_output = input_data[0] * weights['hidden1_node1'][0] + input_data[1] * weights['hidden1_node1'][1]
hidden1_node1_activated = relu(hidden1_node1_output)
# 두 번째 은닉층 계산 및 ReLU 활성화 함수 적용
hidden2_node0_output = hidden1_node0_activated * weights['hidden2_node0'][0] + hidden1_node1_activated * weights['hidden2_node0'][1]
hidden2_node0_activated = relu(hidden2_node0_output)
hidden2_node1_output = hidden1_node0_activated * weights['hidden2_node1'][0] + hidden1_node1_activated * weights['hidden2_node1'][1]
hidden2_node1_activated = relu(hidden2_node1_output)
# 출력층 계산
output = hidden2_node0_activated * weights['output'][0] + hidden2_node1_activated * weights['output'][1]
print(int(output))15
2) 역전파 과정: 예측 오차 계산과 출력층 가중치 기울기 업데이트
target_value = 18
# 오차 계산하기
error = output - target_value
# 예측값에 대한 오류의 기울기
output_error_gradient = 2 * error
# 출력층의 가중치 기울기
output_weight_gradients = [
hidden2_node0_activated * output_error_gradient,
hidden2_node1_activated * output_error_gradient
]
print(output_weight_gradients)[-851.1999999999997, -0.0]
※ 결과 해석
- 첫 번째 요소: -851.1999999999997 이 값은 첫 번째 은닉층 노드(hidden2_node0_activated)와 예측값에 대한 오류의 기울기(output_error_gradient)를 곱한 결과입니다. 이 값은 신경망의 첫 번째 가중치를 증가시키면 실제 목표값과의 오차가 증가할 것임을 나타냅니다. 즉, 이 가중치를 감소시켜야 예측 오차를 줄일 수 있음을 의미합니다.
- 두 번째 요소: -0.0이 값은 두 번째 은닉층 노드(hidden2_node1_activated)의 활성화 함수인 ReLU 함수로 0이 되었기 때문에, 이 노드와 관련된 가중치 기울기가 0이 됩니다. 따라서 두 번째 은닉 노드는 현재 단계에서의 예측값에 대해 활성화되지 않았음을 의미하며, 이 가중치의 조정이 현재 오차에 대해 직접적인 영향을 미치지 않음을 나타냅니다.
- 결론: 이 결과는 첫 번째 가중치를 조정(감소)하여 신경망의 성능을 개선할 수 있음을 나타냅니다. 반면, 두 번째 가중치는 현재 예측값에 영향을 주지 않으므로 업데이트 대상에서 제외할 수 있음을 시사합니다. 이러한 기울기 정보는 신경망의 학습을 통해 가중치를 어떻게 업데이트해야 하는지를 결정하는 데 중요한 역할을 합니다.
3) 역전파 과정: 두 번째 은닉층 가중치 기울기 업데이트

출력층과 은닉층의 기울기 계산에 차이가 있는 주된 이유는 은닉층에서는 다음 층으로 전달되는 오류 신호의 '기여도'를 계산하기 위해, 해당 노드로부터 다음 레이어로의 가중치를 고려해야 하기 때문입니다.
예를 들어, 두 번째 은닉층의 오류 기울기는 출력층으로 가는 가중치 (weights['output'][1]), 출력층의 오류 기울기 (output_error_gradient), 그리고 노드의 ReLU 미분값의 곱으로 계산됩니다.
여기서 weights['output'][1]는 두 번째 은닉층의 첫 번째 노드의 출력층 사이의 연결 강도를 나타내며, 이를 통해 이 노드가 출력층 오류에 얼마나 기여했는지를 판단할 수 있습니다.
이러한 계산은 각 노드가 최종 출력에 대해 어떤 영향을 미치는지를 정량화하며, 이를 바탕으로 가중치를 조정하여 신경망의 성능을 개선합니다.
즉, 은닉층의 가중치 기울기는 이전 레이어의 활성화된 출력값, 해당 가중치를 통해 전달된 오류 기울기, 그리고 활성화 함수의 미분값을 고려한 결과입니다.
이 점을 명심해야 할 것은, 출력층에서는 활성화 함수를 사용하지 않거나 다른 활성 함수를 사용할 수 있으므로, 출력층의 가중치 기울기 계산은 은닉층과 다를 수 있다는 것입니다.
# 두 번째 은닉층의 오류 기울기
hidden2_node0_error_gradient = weights['output'][0] * output_error_gradient * relu_derivative(hidden2_node0_activated)
hidden2_node1_error_gradient = weights['output'][1] * output_error_gradient * relu_derivative(hidden2_node1_activated)
# 두 번째 은닉층의 가중치 기울기
hidden2_weight_gradients = {
'hidden2_node0': [
hidden1_node0_activated * hidden2_node0_error_gradient,
hidden1_node1_activated * hidden2_node0_error_gradient
],
'hidden2_node1': [
hidden1_node0_activated * hidden2_node1_error_gradient,
hidden1_node1_activated * hidden2_node1_error_gradient
]
}
print(hidden2_weight_gradients){'hidden2_node0': [-851.1999999999997, -0.0], 'hidden2_node1': [-0.0, -0.0]}※ 결과 해석
- hidden2_node0의 가중치 기울기: 두 번째 은닉층의 첫 번째 노드 출력에 대한 기울기는 -851.2로, 이 값은 가중치를 업데이트할 때 해당 가중치를 감소시키는 방향으로 조정해야 함을 의미합니다. 두 번째 은닉층의 첫 번째 노드에 대한 두 번째 입력 가중치의 기울기는 0으로, 이 가중치에 대한 조정은 필요하지 않음을 나타냅니다.
- hidden2_node1의 가중치 기울기: 두 번째 은닉층의 두 번째 노드에 대한 모든 입력 가중치의 기울기는 0으로 계산되었습니다. 이는 해당 노드의 출력이 최종 오류에 영향을 미치지 않거나, ReLU 함수의 미분값이 0이어서 오류의 결과가 어떠한 기여도도 하지 않았음을 의미할 수 있습니다.
4) 역전파 과정: 첫 번째 은닉층 가중치 기울기 업데이트
# 첫 번째 은닉층의 오류 기울기
hidden1_node0_error_gradient = (
weights['hidden2_node0'][0] * hidden2_node0_error_gradient +
weights['hidden2_node1'][0] * hidden2_node1_error_gradient
) * relu_derivative(hidden1_node0_activated)
hidden1_node1_error_gradient = (
weights['hidden2_node0'][1] * hidden2_node0_error_gradient +
weights['hidden2_node1'][1] * hidden2_node1_error_gradient
) * relu_derivative(hidden1_node1_activated)
# 첫 번째 은닉층의 가중치 기울기
hidden1_weight_gradients = {
'hidden1_node0': [
input_data[0] * hidden1_node0_error_gradient,
input_data[1] * hidden1_node0_error_gradient
],
'hidden1_node1': [
input_data[0] * hidden1_node1_error_gradient,
input_data[1] * hidden1_node1_error_gradient
]
}
print(hidden1_weight_gradients){'hidden1_node0': [-1.6799999999999997, -0.11199999999999997], 'hidden1_node1': [-0.0, -0.0]}5) 역전파 과정: 은닉층과 출력층의 가중치 조정 및 결과 출력
for key in weights.keys():
if key.startswith('hidden1'):
weights[key] = [w - learning_rate * g for w, g in zip(weights[key], hidden1_weight_gradients[key])]
elif key.startswith('hidden2'):
weights[key] = [w - learning_rate * g for w, g in zip(weights[key], hidden2_weight_gradients[key])]
else: # 출력층
weights[key] = [w - learning_rate * g for w, g in zip(weights[key], [hidden2_node0_error_gradient, hidden2_node1_error_gradient])]
for key, value in weights.items():
print(f"{key}: {value}")hidden1_node0: [50.0168, 10.00112]
hidden1_node1: [-1.0, 0.0]
hidden2_node0: [8.611999999999997, 10.0]
hidden2_node1: [-0.1, 0.0]
output: [0.1056, 25.0]※ 결과 해석
1) 가중치 업데이트
- weights.keys()를 통해 신경망의 모든 가중치 키를 반복합니다.
- if문을 사용하여 키의 이름이 'hidden1', 'hidden2', 또는 출력층을 나타내는지에 따라 해당 층의 가중치를 업데이트하는 조건을 분류합니다.
- 가중치 업데이트는 w - learning_rate * g 공식을 사용합니다.
여기서 w는 현재 가중치, g는 해당 가중치에 대한 기울기, 그리고 learning_rate는 학습률을 의미합니다.
이 공식을 기준으로 기울기의 방향으로 가중치를 조정하여, 손실 함수의 값을 줄이는 방향으로 신경망을 최적화합니다. - zip(weights[key], hidden1_weight_gradients[key])를 사용하여 현재 가중치와 그에 대응하는 기울기를 쌍으로 묶어, 각 가중치에 대해 업데이트를 수행합니다.
2) 가중치 출력
- 업데이트된 가중치는 for key, value in weights.items() 반복문을 사용하여 출력됩니다.
- 이를 통해 가중치가 올바르게 조정되었는지 확인할 수 있습니다.
이 코드는 신경망의 학습을 돕기 위해 가중치를 조정하여 모델의 예측 성능을 개선하는 과정에 사용됩니다.
학습률은 가중치 조정의 크기를 나타내며, 적절한 학습률이 설정되지 않으면 학습 과정에서 손실 함수가 발생할 수 있고, 너무 작으면 학습이 너무 천천히 진행될 수 있습니다.
따라서, 적절한 학습률은 신경망 학습의 효율성과 성공을 위해 중요합니다.
'딥러닝 > 딥러닝: 기초 개념' 카테고리의 다른 글
| Pytorch의 nn.Module과 nn.Linear를 활용한 단순 선형 회귀 모델 구현 (0) | 2025.01.16 |
|---|---|
| Pytorch의 텐서 연산을 활용하여 단순 선형 회귀 모델 구현 (0) | 2025.01.16 |
| 파이썬을 활용한 순방향 전파로 집 가격 예측 (1) | 2025.01.15 |
| 옵티마이저와 드롭아웃 (0) | 2025.01.15 |
| 경사하강법과 학습률 (0) | 2025.01.14 |